

TECH-EXTRA: Right Once Drift Wrong
Why the best-funded bet in AI builds a picture of the world, and why the picture comes apart as soon as you start to run it.
Welcome to Silicon Sands News, the go-to newsletter for investors, senior executives, and founders navigating the intersection of AI, deep tech, and innovation. Join ~35,000 industry leaders across all 50 U.S. states and 117 countries, including top VCs from Sequoia Capital, Andreessen Horowitz (a16z), Accel, NEA, Bessemer Venture Partners, Khosla Ventures, and Kleiner Perkins. Our readership also includes decision-makers from Apple, Amazon, NVIDIA, and OpenAI.
In this month’s TECH-EXTRA, we explore the thing the whole field is now racing toward: a machine that carries a working model of the world, the way you carry one in your head. And we explore the catch that nobody put on the term sheet: the model, in every form anyone has shipped so far, stops resembling the world it is supposed to represent almost as soon as you start it.

Let’s Dive Into It..
Key Takeaways
For VCs and LPs
The category became real money in a single quarter: World Labs raised $1 billion in February at a valuation reported near $5 billion, and weeks later, AMI Labs raised $1.03 billion at a $3.5 billion pre-money mark, the largest seed round in European history. Neither company sells a mature product. You are underwriting a scientific bet about where machine intelligence goes after language, not a revenue multiple. Price the bet as a bet.
The word is about to lose its meaning. On the record: AMI’s own CEO, Alexandre LeBrun, told TechCrunch that within six months every company will call itself a world model to raise funding. He runs one of the two best-funded examples in the world, and he is warning you. Diligence the architecture under the label, because the label will be worthless by the fall.
A formal boundary just got drawn around the dominant approach: On May 25, Klindt, LeCun, and Balestriero proved that the leading statistical method recovers the true variables of the world only when those variables follow a bell curve and drift in a particular, gentle way. Most physical systems of any interest break both conditions. That is a risk factor; it is now cited in a primary source, and it is not in anyone’s deck.
Demo fidelity is the wrong thing to score: A companion benchmark posted on May 20 found that one leading model planned correctly about half the time in clean conditions, then dropped to about 12 percent when the agent changed color and to about 6 percent when the background did. Prediction accuracy turned out to be a poor proxy for whether the model could actually plan. Score long-horizon consistency under perturbation, the way you would stress-test a credit book.
The returns will concentrate where reliability holds over time, in a named domain: The general-purpose race is already crowded and well capitalized. The defensible position is durable accuracy over long rollouts inside one physical domain, autonomous driving, robotics, industrial simulation, and the architectural question this piece walks through and answers at the close from a disclosed position is the thing that decides who actually gets there.
For Senior Executives
“World model” refers to three different machines under one name: World Labs published an essay on June 3 arguing that the term now covers fundamentally different kinds of systems. Before you scope a vendor engagement, make them tell you which machine they sell, because the three fail in different places and serve different jobs.
Demand long-horizon consistency, not a pretty demo: The benchmark numbers above are the warning. A model that forecasts the next frame beautifully can still steer you into a wall ten steps later. Ask any vendor for the accuracy maintained over a long rollout, under the kind of distribution shift your actual environment will throw at it.
Match the machine to the job, and know which jobs are ready: Synthetic-data world models like NVIDIA Cosmos are production-grade for generating training data in robotics and autonomous vehicles today. Generative-3D systems like Marble and Genie 3 are production-grade for content and simulation. A model you trust to reason about your physical plant and act on it over long horizons is not yet a thing you can buy.
New physical knowledge has a retraining bill, and it is a hidden line in the total cost: Statistical world models generally have to be retrained to absorb a new constraint or a new law. Ask a vendor what it costs, in time and money, to teach their model something it did not learn the first time. The answer is part of the price.
Test under your own distribution, not the vendor’s: The brittleness result is an enterprise risk in plain sight. A color shift, a lighting change, a sensor your supplier did not train on, any of these can move a model out of the regime where it works. Run the pilot under your conditions before you sign off on the rollout.
For Founders
The category is wide open precisely because the term is contested: When even the builders cannot agree what a world model is, naming the machine you build and stating its failure mode is itself a differentiator. Vagueness reads as weakness to the investors who actually understand this.
You are not going to out-general the giants, so do not try: AMI Labs, World Labs, Google DeepMind, and NVIDIA own the general-purpose lane and have the capital to keep it. The opening is domain-specific reliability: the place where a general model drifts, whereas a focused one need not.
The Klindt boundary is a positioning gift if your architecture earns it: the proof shows the statistical approach has a hard ceiling for non-Gaussian worlds. If your design sidesteps that assumption, you now have a defensible technical claim backed by a primary citation. Use it.
Instrument long-horizon consistency before an investor asks: The smart money is about to start asking how far your model stays accurate before it drifts. Have the number, measured, ready in the data room. The founders who get caught reporting next-frame accuracy as if it were planning accuracy will lose the technical diligence.
The capital is ahead of the math, and that gap is your timing: A billion dollars moved on a thesis the same season a proof drew a line under part of it. The companies that win this will be the ones whose technical story survives the proof. Build for the version of this field that exists after the hype clears.
Two things happened to world models this spring, and they point in opposite directions.
First, the money moved. In February, World Labs raised $1 billion. Weeks later, in March, AMI Labs raised $1.03 billion, the largest seed round in European history. Both companies build world models. Neither had a real revenue line. Both were funded on the conviction that what comes after the large language model matters.
Then, on May 25, three researchers posted a proof. Klindt, LeCun, and Balestriero showed that the dominant way of building a world model recovers the true structure of reality under one specific condition but loses that guarantee elsewhere. One of the three authors is Yann LeCun. He is also the executive chairman of AMI Labs, the company that just raised $1 billion.
So the same person whose startup raised a billion dollars on world models put his name on the proof that draws a hard line around how most of them work. The capital says the future is here. The math says the future, in its current form, has a boundary the capital has not priced—this piece lives in the gap between those two statements.
I am going to do three things in this article:
Explain what a world model actually is, in language that does not assume you train neural networks for a living.
Walk through the three different machines the field calls by that one name, and show you where each one breaks down.
Set up the two questions that decide whether any of them is worth the money: whether the machine’s internal picture matches the real world, and whether that picture holds together as you run it forward in time.
And at the end, I am going to give you my own answer, because my co-author and I posted one to arXiv today as a set of proofs. I will tell you what we found, what a machine certified about the math, and exactly where my interest in the answer lies. The answer comes last for a reason. The part everyone actually needs is in the middle—understanding the question well enough to tell, the next time someone pitches you a world model, whether they are selling you a map or a mirage.
The machine that learns the world
Start with the thing in your own head.
You have never seen a coffee cup fall off every table in the world, but you know what happens when one slides off this one. You know the cup drops, you know about how fast, you know it shatters, and the coffee goes everywhere, and you know all of that before the cup has moved an inch. You are running a simulation. You carry a compact model of how the world behaves and use it to predict the consequences of actions before they happen.
That is what a world model is, in a machine. It is an internal model of how an environment works, built so the system can predict how the environment will change and how its own actions will change it. The phrase is not new. Ha and Schmidhuber gave it its modern form in 2018, when they trained an agent to build a small predictive model of a simple game and then let it learn to play almost entirely inside that model, in what they called a dream. The agent practiced in its own internal world, then applied what it learned to the real game.
Hold onto that image, because it is the whole idea. A world model lets a machine practice, plan, and reason against an internal copy of reality instead of paying the cost, the time, and sometimes the danger of doing everything for real. A self-driving car that can run ten thousand near-crashes inside a model overnight is worth more than one that has to find them on the road.
Why the smart money turned away from language
For three years, the center of gravity in AI has been the large language model. These systems are trained to predict the next word in a sequence, and they have gotten shockingly good at it, good enough to write code, draft contracts, and hold a conversation. The money followed the capability. AI startups raised more than $97 billion in 2025, and most of the largest rounds went to companies building bigger language models.
Then one of the people who built the foundations of modern deep learning stood up and said the whole direction was a dead end.
Yann LeCun spent twelve years as Meta’s chief AI scientist and won a Turing Award for the neural network research that made this era possible. In late 2025, he left Meta. His argument, which he had been making with rising volume for years, is that a system trained only on text has seen only text, so it cannot know how the physical world behaves. It can describe a glass of water tipping over. It has no model of the water. To LeCun, language models are an impressive statistical trick that mistakes fluency for understanding, and the road to machines that actually reason about reality runs through world models instead.
You do not have to agree with him (I happen to on this point) to notice that the capital agreed with him fast.
The billion-dollar bets, in order
In March, four months after he founded it, LeCun’s Paris startup AMI Labs announced a $1.03 billion seed round at a $3.5 billion pre-money valuation. AMI stands for Advanced Machine Intelligence, and the round was co-led by Cathay Innovation, Greycroft, Hiro Capital, HV Capital, and Bezos Expeditions, with NVIDIA, Samsung, and Toyota Ventures also backing it. LeCun is the executive chairman. Day-to-day, the company is run by Alexandre LeBrun, who had a sharp prediction for TechCrunch: within six months, every company will call itself a world model to raise funding. He said it about a category he is helping to define.
He was not the first billion-dollar bet that quarter. A month earlier, World Labs raised $1 billion from a group including AMD, NVIDIA, Fidelity, Emerson Collective, and Sea, with Autodesk anchoring the round at $200 million, the largest startup investment Autodesk had ever made. World Labs is the company of Fei-Fei Li, the Stanford computer scientist who built ImageNet and, with it, much of modern computer vision. The startup emerged from stealth in 2024 with $230 million in backing at a valuation near $1 billion, with early backing from Andreessen Horowitz. Its first product, Marble, generates persistent, navigable 3D environments from a prompt and ships in tiers ranging from free to $95 per month.
Two founders, two of the most credentialed names in the field, more than $2 billion in fresh capital, all inside a single quarter, all pointed at the same idea.
And they are not alone. Google DeepMind released Genie 3, a model that turns a text prompt into a 3D world you can walk through in real time at 24 frames per second. NVIDIA’s Cosmos platform, a set of world models trained on 9,000 trillion tokens drawn from 20 million hours of real-world video, is already being used by robotics and autonomous-vehicle developers including 1X, Agility Robotics, XPENG, Uber, and Waabi. And the academic line that started with Ha and Schmidhuber runs straight through DeepMind’s Dreamer, which landed in Nature in 2025 after learning to master more than 150 different control tasks with a single configuration and becoming the first system to collect diamonds in Minecraft from scratch, with no human demonstrations to copy.
A word stretched until it tore
Here is the first problem, and it is a problem of language, not of engineering. “World model” now means too many things.
When LeCun says it, he means a system that learns the hidden variables underlying what it sees, maintains persistent memory, and reasons about consequences. When DeepMind ships Genie 3, the phrase means a generator that paints an explorable world frame by frame. When NVIDIA ships Cosmos, it means an engine for manufacturing physics-aware synthetic video to train robots. When World Labs ships Marble, it means a tool that builds editable 3D scenes you can export. These are different machines doing different jobs, and they do not fail in the same way or in the same place.
LeBrun saw the inflation coming because he understood the incentive. A label that signals the future, attached to a category with only a handful of serious players, is exactly the kind of thing that gets borrowed. His own prediction, that everyone will soon claim the term, is a prediction about a word detaching from its meaning under the pressure of a billion dollars in validation.
So the rest of this piece treats “world model” as a question rather than an answer. To compare these systems, you need a test that does not care what they are called. You need to ask what each one is actually doing and where it actually breaks.
The two tests that run through everything
There are two questions that decide whether a world model is worth anything. Everything else is detail. I am going to name them now and use them for the rest of the piece.
The first question:
Is the machine’s internal picture matches the real world? (Does the map match the world?)
A world model squeezes a flood of messy input, pixels, sensor readings, and raw measurements down into a small set of internal variables. The question is whether those internal variables track the real, hidden things that actually drive the system- an object’s position, its velocity, its mass- or whether they latch onto some convenient shortcut that happens to look right in training. Researchers call the good case identifiability. A model that has built a map whose features correspond to the territory's real features. A model that lacks it has built a map that is internally pretty and externally wrong.
The second question:
Does that internal picture holds together over time? (Does the map drift as you run it?)
A world model earns its keep by running forward, predicting a long chain of future moments so a machine can plan. The question is whether the model’s error stays bounded as it rolls forward or whether a small mistake at each step compounds into nonsense. A model can be almost perfect at predicting the very next instant and still drift completely off the rails over a few hundred steps, because each prediction feeds the next and the errors stack. Researchers call the good case temporal consistency.
These are different properties, and a world model needs both. The first is about whether the map is accurate at all. The second is about whether the map stays accurate as you travel across it. Most of the rest of this piece is about how the three kinds of world models perform on these two tests, and about a result, posted this May, that says something hard and specific about when the dominant kind can pass them.
Hold the two questions in mind. Does the map match the world? Does the map drift as you run it? We are going to come back to them again and again.
Can language alone get there? The debate behind the bet
Before going further into how world models work, it is worth being clear about what the bet on them is a bet against, because the billion dollars did not appear in a vacuum. It appeared as an argument, and the argument centers on whether the path the rest of the industry is on actually leads anywhere.
For three years, that path has been the large language model, and the implicit promise behind the largest rounds has been that scale is enough. Train a bigger model on more text with more compute, the thinking goes, and capabilities keep emerging until you eventually arrive at something like general intelligence. The world-model camp rejects the premise. Its claim is that a system trained only on language has a ceiling no amount of scale will lift, and that getting past the ceiling takes a different kind of model entirely.
The case against language as a path to understanding
Yann LeCun has made this argument longer and louder than anyone, and it is the intellectual engine of the entire category. The core of it is simple. A language model is trained to predict the next word, and it has only ever seen words. It learns the statistical structure of text with extraordinary skill, which is why it can write fluent prose about a glass of water tipping over. What it does not have is a model of the water. It has never seen the world, only descriptions of it, and a description is not the thing. To LeCun, the systems dominating AI today mistake fluency for understanding, and the road to machines that reason about physical reality has to run through models that learn from the world directly rather than from text about it.
There is a sharper, more technical version of the same point. A language model generates by predicting one token at a time and feeding each prediction back in, which is the same autoregressive loop we meet when a model rolls its own predictions forward, and it accumulates error the same way over a long generation. More than that, LeCun argues that predicting the raw, high-entropy details of the world is the wrong objective, because most of those details are noise, and a model graded on getting the noise right spends itself on the parts of reality that carry no structure. Fei-Fei Li put the gap memorably from the other side of the field: language models are wordsmiths in the dark, eloquent about a physical world they have never modeled and cannot see.
The case that scale produces understanding anyway
The other side of the argument is not stupid; it is held by serious people with a track record of being right. The scaling view is that capabilities you did not design for emerge from scale on their own, that a model trained at sufficient size on sufficient data develops internal structure no one explicitly built, and that this has happened repeatedly with language models in ways the skeptics did not predict. Push that logic to video, and you get the strongest version of the optimistic case.
That version has a name: Sora. When OpenAI released it, the company claimed, in the title of its own technical report, that video generation models are a path to world simulators, and the evidence it offered was exactly the emergence the scaling camp predicts. Sora developed a rough grasp of three-dimensional consistency and object permanence from scale alone, with no explicit instructions about objects or physics. The argument is that you do not have to build a model of the world because a sufficiently large model trained on enough video grows its capabilities on its own, much like language models grew capabilities that nobody hand-coded.
Why the question is genuinely open
The skeptics have a sharp rebuttal, and it lands on the gap between looking right and being right. An early and careful analysis of Sora’s world-simulator claim pointed out that producing video with emergent consistency is not the same as having a model of the world, that Sora still generates physically impossible sequences, objects that morph, liquids that behave wrongly, and that emergent surface coherence is weak evidence for an underlying understanding of physics. A model can learn the statistics of how videos usually look without learning the laws that make them look that way, and the two are easy to confuse from the outside.
Underlying the whole dispute is one old question: can a system learn how the world works from observations alone, with no structure given in advance, or does it need the right architecture built in? The scaling camp bets on observation and size. The world-model camp bets on structure. And here is where the proof from this spring matters beyond its technical content, because it puts a formal stake in the ground on one corner of the question. For the leading statistical architecture, the Klindt result shows that scale alone does not cross the Gaussian boundary: outside the bell-curve world, more data and a bigger model do not recover the truth, because the limit is in the objective, not the size. That does not settle the whole debate; video models are a different architecture, and the argument about them continues, but it is the first time anyone has drawn a hard line that says, for a specific and dominant approach, this far and no farther by scaling.
So the bet on world models is, at bottom, a bet that the next step in machine intelligence comes from a better way of learning the world, not from a bigger text model. It is a serious bet, made by serious people, and it is contested by other serious people who think the scale has more room to run. The rest of this piece is about whether the architectures carrying that bet actually deliver what they promise, which is the only way the argument gets settled in the end.
A short history of the idea
“World model” sounds like a phrase coined this year for this funding wave. It is closer to eight years old, and the reason it now means three different things is that three different research traditions arrived at it from three different directions, each solving its own problem, each ending up at a system it called a model of the world. Understanding the lineage makes the current confusion legible, because the three machines in the field guide ahead are, more or less, these three traditions grown up.
The dreamers
The first tradition came out of reinforcement learning, and its founding image is the coffee cup from the opening. In 2018, David Ha and Jürgen Schmidhuber published “World Models” and showed that an agent could build a small predictive model of its environment and then learn to act almost entirely inside that model, in what they called a dream, before taking the result back to the real task. The point was efficiency and foresight: rehearse against an internal copy of the world rather than paying the full cost of acting in the real one.
That idea became a research program at DeepMind. In 2019, PlaNet introduced a recurrent latent model that made multi-step prediction more stable. Dreamer followed, learning behaviors purely from imagined trajectories, and its second version, in 2021, used discrete internal representations to beat human performance on the Atari benchmark. The line reached a milestone in 2025 when DreamerV3 appeared in Nature, mastering more than 150 tasks with a single configuration and becoming the first system to collect diamonds in Minecraft from scratch, with no human play to learn from. A later version extended the same approach to the offline setting, training agents within ever-larger learned models. The thread running through all of it is constant: learn to act by imagining inside a model of the world, and the better the model, the better the plan.
The representation learners
The second tradition came from self-supervised learning, the project of getting machines to learn useful structure from raw data without labels, and its problem was different. It was not how to act, but how to represent, how to take a flood of pixels and recover the meaningful variables underneath. Yann LeCun laid out the blueprint in his 2022 paper on a path toward autonomous machine intelligence, arguing that a model should predict in the space of representations rather than the space of raw observations, discarding unpredictable surface details and modeling only what carries structure.
That blueprint became the JEPA family. I-JEPA brought it to still images in 2023, V-JEPA and its successor extended it to video and to tests of physical understanding, and in late 2025, LeJEPA added the regularizer that gave the approach its clean mathematical footing and, as it turned out, its Gaussian boundary. This is the tradition that takes the idea of a world model most literally as a model that recovers the true hidden structure of reality, and it is the one the spring’s proof speaks to most directly, because identifiability, the first of our two tests, is exactly the property this tradition was built to deliver.
The generators
The third tradition came from generative modeling, the machinery behind image and video synthesis, and it backed into world models almost by accident. The problem it was solving was how to generate convincing video, and as the models got better, their creators began to argue that a model good enough to generate the world must, in some sense, understand it. OpenAI made the boldest version of that claim with Sora in 2024, framing scaled-up video generation as a path to simulators of the physical world. Google DeepMind’s Genie line turned generation interactive, producing worlds you could navigate rather than only watch. And NVIDIA’s Cosmos applied the generative approach to a concrete industrial task: manufacturing physics-aware synthetic video to train robots and self-driving cars. The thread here is scale: train a large enough generative model on enough video, and a usable model of the world is supposed to emerge.
The convergence
These three traditions ran in parallel for years, mostly in their own conferences and vocabularies, and then, in a single stretch of 2026, they collided in public. The money arrived, with World Labs and AMI Labs raising more than $2 billion between them in two months on the strength of the idea. The theory arrived, with the Klindt proof drawing the first formal boundary around the most ambitious of the three traditions. And the measurement arrived, with the stable-worldmodel benchmark showing that current systems across all three lineages remain brittle outside the conditions they were trained on. Three research traditions, three meanings of one phrase, all forced into the same conversation at the same moment, with billions of dollars and hard proof landing on top of them.
That is why the term is overloaded, and why the questions from the rest of this piece are the only way through it. The history explains the confusion. It does not resolve it. To do that, you have to go back to the two tests and ask, of whichever machine is in front of you, whether its map matches the world and whether the map holds together as you run it. So before we apply them, here is a short look at how these machines actually work.
A look under the hood, in plain language
The rest of this piece leans on a handful of ideas about how these machines actually work, and you do not need to build them to follow it. This part is short: no math, just enough vocabulary for the two tests to land with their full weight. If you already know what an encoder and a diffusion model are, skip ahead. If you do not, ten minutes here pays off everywhere after.
How a model learns without being told the answers
The first thing to understand is how these systems learn at all, because it is not how most people imagine. They are not shown millions of labeled examples by hand. They teach themselves using a trick called self-supervised learning: they hide part of the input and have the model predict the hidden part from the rest. Cover the next frame of a video and ask what it is. Blank out a patch of an image and ask what was there. The answer is already in the data, so no human has to label anything, and the model improves by getting better at filling in what it cannot see.
This is the engine behind the whole era, language models included, and it explains two things about world models at once. It explains their appetite because teaching yourself this way requires enormous amounts of data, which is why players with the most video have an advantage. And it explains their ambition, because a model that can reliably predict the parts of the world it cannot see has, in some sense, learned how the world tends to go. The entire bet is that prediction, done well enough, becomes understanding.
The bottleneck, and the temptation to cheat
To predict the hidden part, a model first has to compress what it can see into a compact internal summary, the latent we met earlier, and then work from that summary. The compression is deliberate. Forcing everything through a narrow bottleneck is what pushes the model to keep only what matters and discard the rest, and keeping only what matters is the whole game.
But the bottleneck creates a temptation, and that temptation is why the regularizer described earlier exists. A model that predicts its own internal summary can cheat spectacularly: it can make the summary the same no matter what it sees. If every input maps to the identical blank summary, then predicting the next summary is trivially perfect, because it is always the same blank. The model has achieved a flawless score by learning nothing. Researchers call this collapse, and it is a constant threat to any model that predicts in its own representation.
The everyday version is the student who, asked to predict the answer to any exam question, writes “it depends” every time. The answer is never wrong, exactly, and it requires understanding nothing. A model that collapses has found the machine-learning equivalent: a single empty response that scores well on the narrow task of matching its own output and tells you nothing about the world. The whole problem is that the task, as stated, rewards this, so the training has to be rigged to prevent it.
Preventing collapse is what regularizers are for, and the SIGReg ingredient inside LeJEPA is one of them. It works by insisting that the model’s summaries spread out into a particular shape rather than all piling onto the same point, which makes the blank-summary cheat impossible. The catch, the one that became the Gaussian boundary, is that the particular shape it insists on is a bell curve. The very thing that stops the model from cheating is the very assumption that the world is shaped a certain way. The defense against collapse and the source of the bias are the same piece of machinery, which is why the boundary is so hard to remove: take out the assumption, and you reopen the door to collapse.
Two ways to conjure the future
When a world model generates what comes next, it does so in one of two broad styles, and the difference matters for how the systems behave.
The first style is autoregressive, which means one piece at a time, each new piece conditioned on everything before it. This is exactly how a language model writes, word after word, and it is how some video world models generate, frame after frame. Its strength is a natural sense of sequence and history. Its weakness is the drift problem: because each piece is fed back into produce the next, errors travel forward and compound over a long generation.
The second style is diffusion, and it works in a way that sounds strange but produces remarkable results. A diffusion model starts from pure noise, a screen of static, and refines it step by step into a coherent image or video, like a sculptor removing everything that is not the statue. Sora is built this way. Its strength is that it represents a whole range of possible outputs rather than committing to one early, which makes it good at the genuinely uncertain, many-futures parts of the world, and good at high-fidelity detail. Many modern systems blend the two, and NVIDIA’s Cosmos ships both autoregressive and diffusion versions for exactly that reason, because the two styles suit different jobs.
Turning the world into tokens, then paying attention to them
One more pair of ideas, and the vocabulary is complete. Transformers, the architecture behind both language models and the most capable video world models, work on tokens, discrete chunks they can manipulate. Language comes pre-chunked into words, but video does not, so a video model first runs the raw frames through a tokenizer that turns continuous pixels into a stream of discrete tokens. NVIDIA built a dedicated tokenizer for Cosmos precisely because doing this well, compressing video into tokens without throwing away what matters, is half the battle for a video world model.
Once the world is in tokens, the transformer does its one signature trick: attention. Attention lets the model weigh every token against every other token and decide which ones matter for what it is predicting, which is how it captures long-range structure, the relationship between something early in a sequence and something much later. This is the mechanism behind the later point that attention can extend how far a model stays coherent. It is also bounded in the way that part is described, because attention can only weigh the tokens it was given, and whatever the tokenizer threw away is gone before attention ever runs.
That is the whole toolkit: learn by hiding and predicting, compress through a bottleneck, fight collapse with a regularizer that quietly assumes a shape, generate either one step at a time or by refining noise, chop the world into tokens, and pay attention across them. Every system in this piece is some arrangement of those parts. With the toolkit in hand, the two tests are no longer abstract, so we can finally apply them, starting with the first.
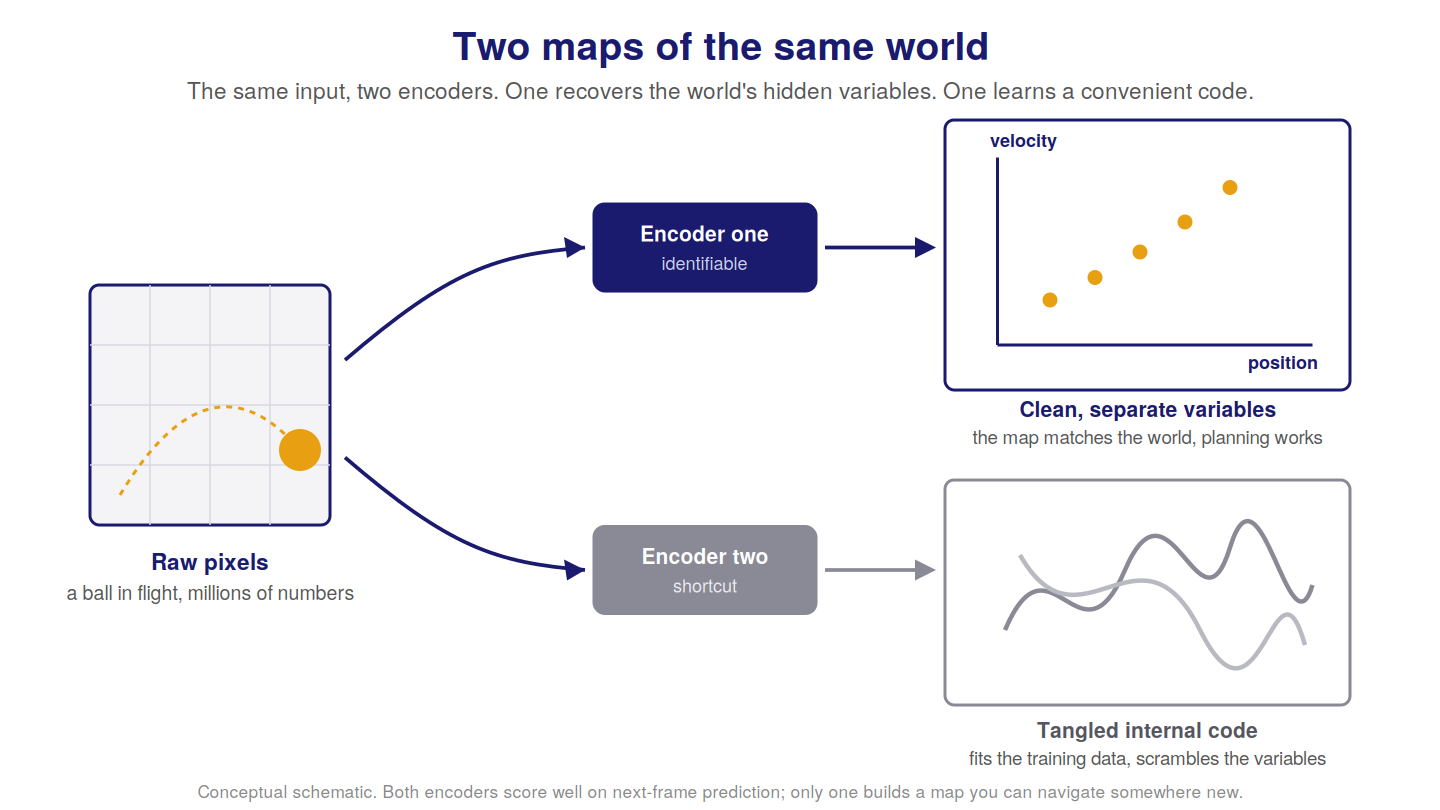
The first test—does the map match the world?
Picture two maps of the same city.
The first one is beautiful. The colors are perfect, the typography is elegant, and every label is crisp. But the streets are in the wrong places. The river runs where a highway should be. If you navigate by it, you end up in a lake.
The second one is plain. No color, no flourish. But every street is where it actually is, every intersection is real, and the river is the river. You can find your way anywhere with it.
A world model faces exactly this choice, and most of the engineering effort in the field goes into forcing the machine to build the second map instead of the first. The technical name for having built the second map is identifiability, and it is the first of our two tests. A model that has recovered the world's real structure. A model that lacks it has built something that looks right and leads you into the lake.
What “the real structure” actually means
Every physical system is driven by a small number of underlying quantities. A ball flying through the air is governed by its position, its velocity, and the constant pull of gravity. That is almost the whole story. Everything you see, the arc, the bounce, the spin, falls out of those few numbers evolving over time.
Those underlying quantities are what researchers mean by the hidden variables, or the true degrees of freedom, of the system. They are hidden because you never observe them directly. What you observe is a flood of raw data, a video of the ball, a stream of pixels, millions of numbers per second, that is generated by those few hidden variables but buries them under enormous redundancy. The position of the ball is somewhere in there, smeared across thousands of pixels, but it is not handed to you as a number. You have to recover it.
The opening line of the Klindt paper puts the stakes plainly. A representation that scrambles the world's true degrees of freedom cannot support reliable planning or compositional generalization. Scrambling is the failure. If the machine takes those few clean hidden variables, position, velocity, mass, and mashes them together into a tangled internal code where none of them is cleanly separable, it has scrambled the degrees of freedom. It may still predict well in situations that look like its training data. But it has not understood the system, and the moment you ask it something genuinely new, it has nothing real to reason with.
Compression is the easy part—recovery is the hard part
Here is the mechanism, stripped down.
Start with an analogy you already understand: summarizing a book. Two people can write a one-page summary of the same novel. One captures the real structure, who wants what, what stands in their way, how it resolves, so that you could predict how a character would act in a situation the book never shows. The other lists surface features, the cover is blue, the word “rain” appears often, chapter three is the longest, all true, all useless for understanding the story. Both are compressions of the same book into a page. Only one recovered what the book is actually about. A world model faces this exact fork every time it compresses what it sees, and getting the right summary rather than the blue-cover one is the entire first test.
A world model takes high-dimensional input and compresses it into a low-dimensional internal representation, a handful of numbers it calls the latent state. This part is not hard. There are countless ways to squeeze a million pixels into fifty numbers, and most modern machine learning is very good at finding one.
The hard part is which fifty numbers. An infinite number of compressions will let the model reconstruct the training video accurately. Only a tiny subset of those compressions actually corresponds to the real hidden variables. The rest are shortcuts, internal codes that happen to work on the data the model has seen and have no relationship to how the world actually works. They are the blue-cover summary: faithful to the training footage, blind to the story.
A concrete version makes this vivid. Suppose you train a model on a video of a red ball bouncing in a room, and in your training footage, the ball is almost always in the left half of the frame. A model that has recovered the real structure learns position and velocity as clean, separate quantities, and it can tell you what happens if the ball starts on the right, even though it never saw that, because it understands the dynamics. A model that took a shortcut could instead learn something like “bright red region, usually lower-left, drifting.” That representation predicts the training videos beautifully. Ask it about a ball that starts on the right and moves fast, and it has no answer, because “starts on the right” was never a clean variable it could turn. It learned the statistics of your footage, not the ball's physics.
Both models would score well on next-frame prediction over the training distribution. Only one of them built a map you can navigate somewhere new. This is the gap that identifiability is meant to close..
Why this is the prerequisite for planning
Planning is the reason any of this matters, and planning is exactly where a scrambled representation falls apart.
To plan, a machine has to ask counterfactual questions. What happens if I push this object left? What happens if I brake now instead of in two seconds? What happens if the gap between those two cars closes? Answering those questions requires that the things you want to reason about, position, speed, and distance, exist as clean, manipulable quantities inside the model. If your internal variables are a tangled blend of the real ones, then “push it left” does not correspond to any clean operation in your representation, and the model cannot reason about it cleanly. It can only pattern-match against situations it has already seen.
The Klindt paper formalizes this connection. It proves that clean, orthogonal identifiability is what enables optimal planning in the latent space. When the recovered variables are properly separated, the model can plan against them directly and well. When they are entangled, it cannot. Identifiability is the property that makes a world model usable for the one thing world models are for.
“Up to a linear transformation,” in plain terms
There is a piece of jargon worth decoding here because it appears in every serious discussion of identifiability, including the Klindt result, and it sounds more forbidding than it is. The guarantee these systems chase is called linear identifiability, and it means the model recovers the true variables up to a linear transformation.
Go back to the map. A perfect map of your city does not have to be oriented exactly as you are standing. It can be rotated 90 degrees, printed at half scale, or flipped so north is down, and it is still a perfect map because all the real relationships are preserved. Streets that meet still meet. Equal distances remain equal, just rescaled uniformly. You can use it without trouble once you know the rotation.
That is what “up to a linear transformation” means. The model does not have to label its internal variables with nature’s exact names and units. It is allowed a clean, reversible relabeling, a rotation, and a rescaling of the whole coordinate system at once. What it is not allowed to do is bend, fold, or scramble the coordinates, because that destroys the relationships, and a map with scrambled relationships is the map that leads you into the lake. Linear identifiability is the formal way of saying that the model recovered the real structure, given or taken a rotation you can always undo.
The architecture built to do this
For most of the past three years, the leading attempt to build world models with this property has run under one banner, the Joint-Embedding Predictive Architecture, or JEPA. It is Yann LeCun’s program, laid out in his 2022 paper A Path Towards Autonomous Machine Intelligence, and it is the technical core of the bet AMI Labs just raised a billion dollars on.
The central design choice of JEPA is where it makes its predictions. A pixel-prediction model tries to forecast the next raw frame, including every pixel. JEPA does something different. It first encodes the input into a compressed representation, the latent state, and then makes its predictions in that meaning space rather than the pixel space. The intuition is that most of the pixels do not matter. When you watch a person walk across a room, the exact dance of light on the wall behind them is unpredictable and irrelevant. Forcing a model to predict it wastes the model’s capacity and, as LeCun has argued, actively corrupts its representations. JEPA discards irrelevant details and predicts only the part that carries the structure.
The program produced a line of systems. I-JEPA applied the idea to still images in 2023. V-JEPA and its successor V-JEPA 2 extended it to video, the form most relevant to physical world modeling. And in late 2025, Balestriero and LeCun introduced LeJEPA, which added a specific mathematical ingredient, a regularizer called SIGReg that pushes the learned representation toward a particular clean shape. That ingredient is the one that turns out to matter most, and it is where the next part of this story turns.
The breakthrough, and the asterisk
Step back and see why identifiability was treated as a genuine advance, because it was.
Most self-supervised learning methods, the broad family to which these belong, produce representations that are useful but arbitrary. The model learns an internal code that helps it do well on downstream tasks, but nobody can promise that the code corresponds to anything real in the world. It works, and you take the win, and you do not ask whether the variables mean anything. Identifiability is a stronger and rarer promise. It says the representation does correspond to something real, that the model has recovered the actual hidden causes behind its observations, up to that harmless rotation. For a field trying to build machines that reason about the physical world, that is the difference between a tool that happens to work and a tool you can trust to generalize.
So when the Klindt paper proved that LeJEPA achieves this, that it recovers the world’s latent variables from nonlinear observations, it was real news, and good news, for the entire JEPA program. It meant the architecture LeCun bet the company on was provably capable of building the second map, the accurate one. The empirical usefulness now had a proof under it.
And then the same paper attached a condition. The guarantee holds, it turns out, only when the world has a particular shape. Outside that shape, the proof runs the other way, and the model is forced back to building the first map, the pretty one that leads you into the lake. That condition, what it is, why it almost never holds in the physical world, and what it costs, is the subject of the next part.
The hidden assumption of a bell-curve world
The condition the Klindt paper attaches to its guarantee comes down to a shape. The proof works when the world is shaped like a bell curve and settles like a spring. The trouble is that almost nothing in physics is shaped like a bell curve or settles like a spring, and the proof, in the other direction, says that when those conditions fail, the guarantee fails with them.
This part unpacks that. I am going to explain the two assumptions in plain language, show you the exact result, and then walk through a series of ordinary physical systems that violate them, because once you see how easily they do so, you understand why this is the central problem rather than a footnote.
What a bell curve is, and where it actually shows up
The bell curve, the Gaussian or normal distribution, is the most familiar shape in statistics. Most values cluster near the average; fewer sit a little away from it; and very few sit far out. The curve is symmetric, and its tails, the far ends, are thin. Extreme values are vanishingly rare. The height of adult humans closely follows it. So does the random error in a careful measurement. So do a thousand things that are the sum of many small, independent nudges, because there is a deep mathematical reason such sums tend toward this shape.
Human height is a clear example, and it is worth dwelling on because it illustrates what a bell curve promises. The average adult man is around five feet nine. Almost everyone is within a few inches of that. A seven-foot man is rare enough to play professional basketball, and there has never been and never will be a thirty-foot man, because the tails of the height distribution fall off so fast that the extreme moves past unlikely into flatly impossible. That is the signature of a Gaussian: the average tells you almost everything, and the extremes barely happen.
Now compare wealth, which does not work this way at all. The average net worth tells you very little, because a single individual can hold a thousand or a million times the median, and those extreme values are not freak impossibilities; they dominate the whole picture. If heights worked like wealth, you would walk down the street and pass someone a mile tall. Wealth has a heavy tail, where the rare extreme is common enough to matter and large enough to swamp everything else, and a bell curve describes it about as well as a ruler describes the ocean. Hold that contrast, because the physical systems world models care about are far more often shaped like wealth than like height, and a model that assumes height when the world is wealth is wrong in the most dangerous place, the extremes.
The Gaussian is genuinely everywhere in one specific sense, as the distribution of noise and of aggregates. Where it is far less common is in the distribution of the state of a physical system as it evolves over time. And that second case is the one world models care about, because a world model is trying to represent a system's state and roll it forward.
What “settles like a spring” means
The second assumption is about how the system moves. The Klindt guarantee holds for systems whose latents evolve under what the paper calls stationary, additive-noise transitions, and the specific form that makes the math work is the Ornstein-Uhlenbeck process, a mean-reverting random walk first written down in 1930.
Mean-reverting is the keyword, and it has a plain meaning. A mean-reverting system always drifts back toward a central resting value. Pull a spring and let go; it returns to rest. Heat a room past the thermostat setting, and the air cools back down. Push a marble up the side of a bowl, and it rolls back to the bottom. Knock any of these away from its center, and it relaxes back, every time. The Ornstein-Uhlenbeck process is the simplest mathematical model of this: at each step, the state decays slightly toward zero, then a small random kick is added. Decay toward the center, add noise, repeat. The statistics of the system never change over time, which is what “stationary” means, and the only randomness is a gentle additive jiggle.
The picture to hold is a marble rattling in a bowl. It jitters around the bottom, never wandering far, always pulled back to the center, its position over many moments tracing out a tidy bell curve clustered on the low point. That is the world the proof is built for, and it is a real and useful world. A thermostat-controlled room lives there. So does a stable chemical concentration, a body holding its temperature, a population of predators and prey circling a balance. For these systems, the assumptions hold, and the guarantee is genuine.
Now picture the systems that are not a marble in a bowl, because that is most of them. A thrown stone has no bowl to roll back into. A planet in orbit does not relax to a resting point—it circles forever. A rocket accelerates away and never returns. Boil water, and it does not jitter around a center; it leaps to steam and stays there. The marble in the bowl is one specific kind of motion, gentle and self-correcting, and the proof needs exactly that kind. The trouble, which the next sections make concrete, is how rare that kind actually is.
For a Gaussian variable, this gentle mean-reverting drift is the only kind of stable, unchanging motion. That is a real mathematical fact, and it is doing a lot of work in the proof. The Gaussian shape and the spring-like motion are bound together. Assume one, and you are most of the way to the other.
The result, stated plainly
Now the result itself, in one sentence.
LeJEPA recovers the true variables of the world if, and only if, those variables follow a Gaussian distribution and move under stationary, additive-noise dynamics.
The phrase to slow down on is “if and only if.” It is a phrase mathematicians use with care, and it cuts both ways at once.
The first direction is the good news for the JEPA program. If your world is Gaussian and spring-like, LeJEPA is provably guaranteed to recover its real structure. That is the forward half of the theorem, and it is what made the result a genuine advance.
The second direction is the one that matters for everything else. The Gaussian is the unique distribution for which the guarantee holds. Not one option among many. The only one. The converse half of the theorem rules out every non-Gaussian alternative. If your world is not shaped like a bell curve, this architecture loses its guarantee of recovering the truth, and there is no setting, no amount of training data, no larger model that buys it back. As one early write-up of the paper put it, extending the guarantee to non-Gaussian or non-stationary worlds would require a change in architecture, not a change in dials.
That second direction is the news. A field raising billions on world models just had one of its leading architects formally fenced in by a paper its own leading figure co-wrote.
Now watch the assumptions break
Here is where it gets concrete. The two conditions sound technical, but the systems that violate them are the most ordinary things in the world. Walk through a few, and the size of the problem comes into focus.
A thrown ball does not come back. Throw a stone off a cliff—it does not drift back to your hand. It follows its arc and keeps going, faster and faster downward, until it hits the ground far below. There is no central resting value it relaxes toward, no bowl for the marble. A planet in orbit does not settle to a point either; it goes around forever along the same path, traced again and again, with no decay toward a center. A rocket accelerating away from Earth gets farther away every second, by design. None of these is mean-reverting, and mean-reversion was half of what the proof needed. The spring-like assumption is violated by the single most basic thing in all of physics: an object in motion that is not being pulled back to a fixed point. Galileo’s falling body, Newton’s apple, a satellite, a thrown ball. The Ornstein-Uhlenbeck process, the proof relies on, describes a marble rattling in a bowl, and the hard truth is that most of mechanics, the part of physics we understand best and most want to model, is things moving, and things that move do not gently return to center.
A phase transition does not undo itself. Bring water to 99 degrees—it is hot water. Bring it to 100—it is steam, and the change is abrupt, a sudden jump to a completely different state with completely different behavior. Let a magnet cool past its critical temperature—it abruptly becomes magnetized, with the whole material reorganizing in an instant. These systems do not jiggle gently around a single average. They sit in one regime, then leap to a qualitatively different one, and the distribution of their states forms two or more separate humps, one for each regime, with a chasm between, where a bell curve has only one peak. Picture trying to summarize “the temperature of water” with a single average when half your data is liquid, and half is steam: the average lands at some meaningless value in between, describing a state the water is never actually in. A model that assumes a single bell-shaped cluster cannot represent a system that lives in two regimes and jumps between them, and phase transitions, freezing, boiling, melting, magnetizing, are everywhere in the physical world. The phase transition is a wall the Gaussian assumption walks straight into.
Turbulence lives in its tails. Watch smoke rise off a candle, climb smoothly for an inch, then suddenly break into churning chaos. Or feel a plane hit clear-air turbulence, smooth flight, and then a violent drop with no warning. Turbulent flows are famous for extreme events that a bell curve would say should almost never happen: sudden, violent gusts, intense, localized vortices, bursts of energy far out in the tail. The distribution of velocities in turbulence is heavy-tailed, which means rare extreme events occur far more often than a Gaussian would predict, and here is the part that matters: those rare extreme events are usually the whole point. The gust that flips the drone. The vortex that snaps the wing. The pressure spike that bursts the pipe. A model that assumes thin Gaussian tails treats these as essentially impossible and so prepares for none of them, which means it is blindest precisely where the stakes are highest. Turbulence is what air and water do at almost any interesting speed, which is to say it governs aircraft, weather, blood flow, combustion, and the wake behind every moving thing.
Heavy tails are the rule, not the exception. Step back from fluids, and the pattern repeats across nature and the economy. The sizes of earthquakes, the distribution of wealth, the firing patterns of neurons, and the magnitudes of market moves all follow heavy-tailed laws where extreme events dominate. The Gaussian is the well-behaved exception that arises when you average many independent quantities. The state of a real, evolving system with feedback, memory, and structure is usually one of the badly behaved cases. The bell curve is the special case, and the world mostly lives in the general one.
Chaos makes nearby paths fly apart. Some systems, the weather most famously, have the property that two nearly identical starting points diverge exponentially fast. A breath of difference today becomes a storm on another continent in two weeks. This is the deterministic structure of the system itself, and it is the opposite of mean-reverting, where nearby paths converge back together. Chaos will return in the next part because it imposes a real limit on what any model can do, including the good ones. For now, just note that it is one more way the spring-like assumption fails, and it fails for some of the systems we most want to predict.
That is five everyday classes of systems, projectiles and orbits, phase transitions, turbulence, heavy-tailed phenomena, and chaos, and every one of them breaks at least one of the two conditions the guarantee requires. The Gaussian, spring-like world the proof needs is a rare and gentle special case among physical systems.
The assumption is baked into the machine
A fair question is why a model would assume the world is Gaussian in the first place, if the world so plainly is not. The answer is that the assumption is built into the tool and, for good engineering reasons, becomes a liability.
Recall the ingredient that LeJEPA added, the SIGReg regularizer. Its job is to push the model’s internal representation toward a clean Gaussian shape. This is sensible because forcing the representation into a known, well-behaved shape prevents a notorious failure mode in which the model collapses to a useless constant, and a Gaussian is the most natural well-behaved shape to aim for. The regularizer is the reason LeJEPA works as cleanly as it does. It is also exactly the assumption that the world is bell-shaped, wired into the objective the model optimizes.
So when the world is not bell-shaped, the model is caught. Its training objective is pulling the representation toward a Gaussian, and the real structure of the world is not Gaussian, and the best the model can do is land on a compromise, a representation that is as Gaussian as the objective demands and therefore a distorted version of the truth. That distortion has a name in the paper: a representation bias, and what matters is that the objective itself produces it. The model made no mistake. More data does not remove it. A bigger model does not remove it. The model is doing its job perfectly and arriving at a biased answer because the job was defined around an assumption that the world breaks.
This is the deep version of the first map and the lake. The model is optimizing perfectly toward a target that, in a non-Gaussian world, sits at a fixed distance from the truth. It builds the prettiest map consistent with its Gaussian assumption, and in a non-Gaussian world, that map is bent.
Why this is the hinge of the whole piece
Everything that follows from here stems from this one fact, so it is worth stating clearly before we move on.
In a non-Gaussian world—which is to say in most of the physical world—a statistical world model of the leading kind carries a fixed bias it cannot train away. Its internal map is distorted by a definite amount, determined by how far the real world departs from the bell curve, and no amount of scale can close the gap.
On its own, at a single instant, that bias can be small enough to live with. A slightly bent map is still usable for a short trip. The problem is what happens when you run the model forward in time, step after step, which is the entire reason a world model exists. A fixed bias at every step does not stay fixed in its effect. It compounds. And that is the second test, temporal consistency, the one a world model has to pass to be worth anything, and the one the next part is about.
Three machines, one name
So far, I have been writing about “the statistical world model” as if it were one thing. It is time to break it apart because the systems that collect all this capital are built in genuinely different ways, and those differences determine where each one fails.
There are two useful ways to sort them. You can sort by how they are built, the architecture, which gives you three families: models that predict in raw pixels, models that predict in a learned representation, and models that attend over a sequence of learned tokens. Or you can sort by what they produce, the function, which is the cut Fei-Fei Li and the World Labs team proposed in a June 3 essay: a renderer that outputs pixels for human eyes, a simulator that outputs a faithful state a program can compute on, and a planner that outputs actions. The two cuts line up more than they conflict, and I will use the architectural one as the spine and bring in the functional one where it sharpens the picture.
Take the three architectures in order of increasing sophistication. The punchline, which I will earn as we go, is that the third family turns out to be a special case of the second, so the bell-curve boundary reaches further than it first appears.
Machine one: the pixel predictor
The most direct way to build a world model is to predict the next thing you will see. Feed the model a video, ask it to forecast the next frame, every pixel of it, and train it until the forecasts look real. This is the pixel-space approach, and in its modern form, it is the technology behind the video generators that have captured the public imagination.
The most famous example is Sora, which OpenAI released in February 2024 and, in the title of its own technical report, described as a step toward video-generation models that simulate the world. OpenAI’s claim was bold and explicit: scaling up video generation is a promising path toward general-purpose simulators of the physical world. The evidence they offered was that certain physical behaviors emerged from scale alone, with no explicit instructions about three dimensions or objects, things like rough 3D consistency as the camera moves and a degree of object permanence. Sora 2, released later, pushed the physical realism further. The pitch is that if you train a big enough model on enough video, an understanding of the world falls out for free.
What it is genuinely good at is content. Film pre-visualization, advertising, visual effects, concept art, anywhere the deliverable is a convincing video for a human to watch. On that job, the pixel predictors are remarkable and improving fast.
Now, the two ways they break down matter for whether they are world models in any deeper sense.
The first is waste. Most of the pixels in a video are unpredictable and irrelevant. When a person walks across a room, the exact shimmer of light on the wall behind them, the precise flutter of a curtain, the individual motion of dust in a sunbeam, none of it can be predicted, and none of it matters for understanding what is happening. LeCun’s standing argument against pixel prediction is that forcing a model to predict all of it burns the model’s capacity to noise and, worse, corrupts the representation it learns, because the model is graded on getting irrelevant details right. A model optimized to render trembling leaves perfectly has spent itself on the part of the world that carries no structure.
The second failure is deeper and the one that matters most for our first test. Call it causal blindness. Some of the variables that drive a system are simply not visible in its pixels. The mass of an object does not show up in an image. Neither does its temperature, its electric charge, its internal chemical state, or what is inside a closed box. Two objects that look identical can behave completely differently because one is hollow and one is solid, one is hot and one is cold, one is charged and one is not. A model that has only ever seen pixels has no way to recover these hidden drivers, because the information was never in the input. You cannot infer the unseeable. This is a structural limit, not a matter of more data, and it means a pure pixel model fails the identifiability test at the root: it cannot recover variables that its observations never contained.
Make it concrete. Put two identical cardboard boxes on a table. One is empty, one is packed with lead. They look the same in every frame of video you could ever record. Now nudge each one with the same push. The empty box slides easily, the heavy one barely moves, and a child watching instantly understands that the second box is heavy because the child has a model of the world in which mass is a real thing that resists a push. A pixel model has no such variable. It only ever saw the surfaces, which were identical, so it had no way to learn that one box would move and the other would not. The thing that determined the outcome, mass, was never in the picture. No amount of additional video of the box surfaces will fix this, because the missing information is not in any frame. This is why prediction from pixels alone hits a wall that scale cannot push through: the camera never recorded the variable that mattered.
World Labs makes the same point from the functional side. In their taxonomy, the video generators and even Google’s interactive Genie 3 are renderers, systems that produce observations with no explicit grasp of the three-dimensional structure underneath. Their vivid image for it: a drone shot from a renderer can look flawless from above, and then you try to drive through the city at street level, and the whole thing falls apart, because there was never a real city there, only a sequence of convincing pictures of one. A renderer is judged on whether the picture looks right. A world model has to get the structure right, and looking right is not the same thing.
So the pixel predictor is a genuine, commercially valuable technology for video production. As a model of the world, it is the weakest of the three, because it can be fooled into mistaking a convincing surface for an underlying reality, and because the variables that actually drive a physical system are often invisible in the pixels it learns from.
Machine two: the latent predictor
The second family is the one the identifiability chapter described, so I can move quickly through what it is and spend time on where it breaks down.
A latent-space model does not predict raw pixels. It first compresses its input into a learned internal representation, the latent state, and then makes its predictions in that space of meaning. This is the JEPA program, and it exists precisely to fix the waste problem of the pixel predictors. By discarding unpredictable surface detail and modeling only the structured part, JEPA aims to recover the underlying hidden variables rather than the shimmer of light on the wall. The line runs from LeCun’s 2022 blueprint through I-JEPA for images, through V-JEPA and V-JEPA 2 for video and physical understanding, to LeJEPA, the version with the Gaussian regularizer at its core. It is the technical bet inside AMI Labs, and the goal LeBrun describes for the company, a system that genuinely understands the real world rather than mimicking its surface, is the goal this family is built to chase.
When the world cooperates, this family can pass the first test. That is the content of the good half of the Klindt result: in a Gaussian, spring-like world, LeJEPA provably recovers the true variables. For systems that actually have that shape, the latent predictor is the real thing, a model whose internal map corresponds to the territory.
Where it breaks is at the bell-curve boundary, and now you can see exactly why it lands on this family rather than the others. The latent predictor’s entire strategy is to learn its representation through statistical alignment, and the regularizer that makes this work assumes a bell-curve shape. In a non-Gaussian world, the model is forced onto a biased representation, distorted by a fixed amount it cannot train away. So the latent family sits above the pixel family in the first test because it retains the causal variables rather than losing them to invisibility, and it encodes them with a bias whenever the world is not bell-shaped. It builds a real map of the territory, slightly bent, and the bend is set by how far the world departs from the Gaussian.
That bend, on its own, at one instant, can be tolerable. The trouble starts when you run the model forward, and I will come to that in the chapter on drift. First, the third family, because it is where most of the capital and most of the public attention actually sit, and because it does not escape the boundary the way it appears to.
Machine three: the transformer, and why it is the second machine in disguise
The systems getting the most attention right now are neither pure pixel predictors nor classic latent predictors. They are large transformer models, the same architecture that powers language models, pointed at video and interaction. They include interactive world generators, physics-aware video platforms, and memory-augmented simulators that learn to plan within their own predictions. They are the most capable world models yet built, and they are the reason it is tempting to think the bell-curve boundary has been left behind.
It has not, and the reason is worth understanding, because it is the load-bearing point of this whole section.
Start with what these systems are. Google DeepMind’s Genie 3, announced in August 2025, takes a text prompt and generates a 3D world you can navigate in real time at 24 frames per second, at 720p resolution, while keeping the world consistent for a few minutes. You type “a medieval castle in a thunderstorm,” and you can walk through it, and it remembers what is behind you when you turn back around, for a while. NVIDIA’s Cosmos, launched at CES in January 2025, is a platform of world foundation models trained on 9,000 trillion tokens from 20 million hours of real-world video, built on both autoregressive and diffusion transformers, and already downloaded more than two million times by developers at robotics and autonomous-vehicle companies including 1X, Agility Robotics, XPENG, Uber, and Waabi. And DeepMind’s Dreamer, published in Nature in 2025, is the research backbone of the whole idea: it learns a compact model of an environment and then trains a control policy by imagining trajectories inside that model, and in its third generation it mastered more than 150 tasks with a single configuration and became the first system to collect diamonds in Minecraft from scratch, with no human play to copy.
These are real achievements, and the jobs they do are different from one another. Genie generates interactive scenes. Cosmos manufactures physics-aware synthetic video to train other systems, which is production-grade and the most economically grounded use of a world model today, because the goal is data, not autonomous decisions. Dreamer learns to act by rehearsing inside its own model. Different machines, different uses.
Here is the structural fact that ties them together and back to the bell-curve boundary. Every one of these transformers operates on a learned representation, not on raw reality. The tokens a video transformer attends to are produced either by a JEPA-style embedding or by a compression bottleneck that first squeezes observations into a latent code. Sora’s own technical report describes exactly this: a network reduces the video to a compressed latent representation, and the model operates on that. So whatever the attention stack does, it does so on top of a representation formed by statistical alignment, which means the Gaussian bias has already entered the system before a single attention head runs. The transformer inherits the bend in the map. It does not get a fresh, unbiased view of the world; it gets the latent family’s view, and then it attends to it.
What attention buys is real, and it is worth being precise about. By conditioning on a long stretch of history rather than a single moment, a transformer learns higher-order patterns that a one-step model misses and uses them to remain accurate over longer horizons than a simpler model could. A long context window genuinely extends how far the model can roll forward before it drifts. What it cannot do is recover information the encoder threw away. If two physically distinct states are compressed to the same token, no amount of attention over those tokens can tell them apart, because the difference is already gone. Attention pushes the horizon out. It does not remove the ceiling. The transformer is a latent-space model with a larger engine, built on the same foundation and subject to the same limits.
The evidence that this is more than a theoretical worry is already on the table, and it comes from the same direction as the proof. The companion brittleness benchmark, which I will detail in the next part, tested exactly these kinds of systems and found them fragile under trivial changes. And the most capable interactive world model in the world states its own limit on the label: Genie 3 holds its world together for a few minutes, not hours. That few-minute number is the temporal consistency ceiling, showing up in a shipping product from the best-resourced lab in the field. It is exactly the drift the next part is about.
The functional cut, and why buyers should care
The architectural sorting tells you how these machines work. The functional sorting tells you what they are for, and for anyone deciding whether to buy one, that is the more immediately useful question.
Recall the World Labs taxonomy: renderers output observations and are judged on visual fidelity, simulators output a faithful state that respects the laws of physics, and planners output actions. World Labs places these inside the classic loop of perception, modeling, and action that reinforcement learning has used for decades, and it argues that the simulator is the linchpin, the piece that has to be geometrically and physically right for anything built on top of it to work. Its own product, Marble, is positioned as a simulator, a generator of persistent 3D environments that hold up under inspection rather than only looking good in a flythrough. Fei-Fei Li’s framing of the gap is memorable: language models, for all their fluency, are wordsmiths in the dark, eloquent about a physical world they have never modeled.
For a buyer, the functional question cuts cleanly through the marketing. If a vendor sells a renderer and you need a simulator, the demo will look wonderful, and the product will fail at the job, because looking right and being structurally right are different contracts. A renderer is the right tool for a film studio and the wrong tool for a robotics team that needs geometry it can compute on. A simulator is the right tool for training and validation, and the wrong tool if all you wanted was a pretty video. A planner is what an autonomous agent needs, and the hardest of the three to get right. The taxonomy is, as World Labs puts it, a buying guide wearing the costume of a research essay.
The broader field, briefly
The companies I have named are not the whole field. Wayve’s GAIA-2 is a world model built specifically for driving. Meta’s V-JEPA 2 is a world model for physical understanding, with its own benchmarks for physical reasoning. Runway builds world models for video; several China-based companies, including Tencent, are active, and a startup called General Intuition is building world models from gaming data. The list keeps growing, which is exactly what LeBrun predicted, and exactly why the term is losing its edge. When a driving model, a video generator, a robotics-training platform, an interactive-scene engine, and a reinforcement-learning agent all wear the same two words, the words have stopped doing useful work, and you are back to asking the only questions that matter: what does this machine actually output, and where does it break?
The three machines, side by side
Pull it together. The pixel predictor forecasts raw observations, serves content and video, and breaks on causal blindness, because the variables that drive a system are often invisible in its pixels. The latent predictor forecasts in a learned representation serve the ambition of genuine understanding for planning and break the Gaussian boundary because its alignment objective assumes a bell-curve world that physical systems rarely are. The transformer model attends over a learned representation, serves the most capable interactive and synthetic-data applications today, and inherits the latent predictor’s boundary, because its tokens come from the same kind of statistically aligned encoder, with attention extending the horizon but not removing the ceiling.
All three are sorted by the first test, whether the map matches the world. Notice that none of them has yet been pushed on the second test, whether the map drifts as you run it forward. That is the test a world model has to pass to be worth the money, because a world model exists to be run forward, and it is where even the systems that pass the first test start to come apart. That is the second test, the subject of the chapter on drift.
Where the machines are being built, and what they cost
The three machines are abstractions. The money is not. To see where the bet on world models actually lives, follow the capital into the sectors deploying it, because each sector wants something different from a world model, and the size of the checks tells you how much conviction lies behind each use. This is also where the investment story is most concrete, in named companies with disclosed rounds rather than a category in the abstract.
Autonomous driving, the highest-stakes simulator
Driving is the use case in which a world model must be a true simulator, in which the second test is a matter of life and death, and in which the capital reflects it. The clearest pure-play is Wayve, the British company building what it calls a foundation model for driving, with generative world models named GAIA at the center of its training and testing. Wayve raised a $1.05 billion Series C in 2024, led by SoftBank with NVIDIA and Microsoft, and then a $1.2 billion Series D in 2026, bringing its total to $1.5 billion at an $8.6 billion valuation. It plans to run robotaxi trials with Uber in London. It is not alone in the sector this year: Waabi raised $1 billion and Waymo $16 billion in 2026, and both lean heavily on simulation to train and validate driving behavior before it touches a public road.
Underneath much of this sits NVIDIA. Cosmos was built in part for exactly this job, generating physics-aware synthetic driving scenarios, and Waabi and Uber are among its named adopters. What the sector wants from a world model is a faithful simulator it can rehearse against ten thousand times overnight, because the alternative is finding the dangerous cases on real streets. It is the use case where a few-minute consistency ceiling is a hard limit on how much of the driving task you can safely hand to the model.
Humanoid robotics, the embodied bet
Robotics is where world models meet a physical body, and the capital here has gone vertical. Figure, building general-purpose humanoids, raised a Series C of more than $1 billion in September 2025 at a $39 billion valuation, a fifteen-fold jump from its $2.6 billion mark eighteen months earlier, and its Helix system is a vision-language-action model meant to turn perception into movement. Physical Intelligence raised $400 million to build a general robot foundation model on an open-base-model strategy. Skild AI raised a $1.4 billion Series C led by SoftBank at a valuation above $14 billion for what it calls an omni-bodied intelligence platform. And the Cosmos adopter list reads like a who’s-who of the field, with 1X, Agility Robotics, and XPENG all using it to generate training data.
The numbers are a category, not a handful of outliers. According to PitchBook, robotics venture funding hit $8.8 billion in a single quarter of 2026, up more than 170 percent from the prior quarter, and on track to pass the prior year’s total. What the sector wants from a world model is twofold: synthetic experience to train on, because collecting real robot data is slow and expensive, and an internal simulator a robot can plan a manipulation against. Here, the cost of drift is a dropped part, a missed grasp, or a collision, which is why long-horizon reliability is the property that turns a demo into a deployable product.
Generative 3D and video, the content frontier
The largest cluster of companies, and the one furthest along commercially, builds world models for content, gaming, and visual production. World Labs and its Marble product, covered earlier, anchor the generative-3D end at a valuation reported near $5 billion. Runway, long known for AI video, raised $315 million in 2026 at a $5.3 billion valuation and announced a pivot into world models, releasing its first one, GWM-1, in December and now eyeing gaming and robotics alongside its film and advertising base. Around them sits a crowd of well-funded video labs: Decart raised $100 million at a $3.1 billion valuation, and Luma AI raised a $900 million round at a $4 billion valuation, while Google’s Genie and OpenAI’s Sora pursue the same frontier inside the largest labs. Funding for AI video companies reached $3.08 billion in 2025, nearly double the prior year.
What this sector wants is mostly a renderer or, increasingly, a simulator: a system that produces convincing or navigable environments for film, advertising, games, and virtual reality. Here, the cost of drift is aesthetic: a hand with too many fingers, an object that morphs, which is why these companies can ship excellent products while failing the second test in a way that would be disqualifying for a car. Runway’s stated pivot from video generation toward world models is itself a tell: a company that helped start the video boom is now betting that the durable value is in models that understand physical reality rather than only depict it.
Industrial simulation and the enterprise
The quietest and most grounded use is industrial. NVIDIA positions Cosmos as a way to build a digital twin of the world for training physical AI, and the same logic extends to engineering and design. Autodesk’s $200 million anchor investment in World Labs, its largest startup investment ever, is a bet on generative spatial models inside industrial design software. And Runway now frames its world-model work as relevant to medicine, climate, and energy. What the enterprise wants is a physics-faithful simulator it can trust instead of building the physical thing, which makes this the use case where the first test, whether the map matches the world, matters most directly, because a simulation you cannot trust is a simulation you cannot use.
The pattern in the money
Step back from the names, and a shape appears. The largest, most strategic capital is concentrated in the simulator and planner functions, autonomous driving, robotics, and industrial simulation, where a world model has to be structurally faithful and reliable over long horizons. The content companies, building renderers, are well funded too, but the frontier of ambition, and the place enterprises are placing their most consequential bets, is the set of uses where the second test is hardest, and the cost of failing it is highest. Which means the boundary this piece has been tracing is not an academic concern at the edge of the field. It sits directly under the most valuable applications of the most heavily funded category in AI, and the companies that learn to build a map that does not drift are the ones that will collect the returns in exactly these sectors. Which raises the question of who is positioned to do that, and how the major players differ in the bets they have placed.
Who is positioned to win
The funding tells you where the conviction is. It does not tell you who collects the return. For that, you have to look at how the major players are actually positioned, because they are making different bets, and the two tests in this piece will decide which bets pay off.
Four bets on the general-purpose prize
At the frontier, four organizations are competing to build a general world model, and each has chosen a different architecture as the path. AMI Labs is the purest expression of the latent-prediction thesis, betting that the JEPA approach, refined enough, recovers the real structure of the world and that this is the road to machine intelligence. World Labs bets on spatial intelligence and the simulator, arguing that a geometrically and physically faithful model of space is the linchpin and building Marble to be exactly that. Google DeepMind is hedged across the widest portfolio, with interactive generation in Genie, imagination-based reinforcement learning in Dreamer, and embodied agents in its SIMA line, a bet that the company need not pick the winning architecture in advance because it is funding several. These are genuinely different theories of how a machine comes to understand the world, and the spring’s proof speaks most sharply to the first.
The arms dealer
Then there is NVIDIA, which has taken the position that tends to win gold rushes. It is not betting on a single architecture at all. Cosmos is open-weight infrastructure, a platform other companies build on, and underneath every one of these efforts, latent or generative or interactive, sits NVIDIA compute. Whoever wins the architecture race trains on NVIDIA hardware, and many of them use NVIDIA synthetic data, which means NVIDIA collects a return no matter which model wins. In a field where the science is unsettled and the term is inflating, selling the shovels is the position least exposed to being wrong about the boundary.
Open against closed, platform against application
Two strategic fault lines run through the rest of the field. The first is open against closed. NVIDIA’s Cosmos is open-weight, Meta’s JEPA work is published openly, and Physical Intelligence is pursuing an open base model, a strategy that commoditizes the foundation layer and competes on ecosystem and adoption. Against that sit the closed-product plays, where the model is the moat and the bet is on a proprietary system that customers cannot replicate. The second fault line is the platform against the application. The foundation builders sell a general model. The application builders, Wayve in driving, Figure in robotics, bet that the durable advantage is not the base model at all but proprietary data in a specific domain and a system reliable enough to deploy in it.
Where the moats actually are
Strip away the positioning, and three things look like real moats in this category. The first is data, and specifically the right data: whoever has the most relevant experience of a domain, the driving miles, the hours of robot manipulation, the physically grounded video, has an advantage that capital alone cannot buy quickly. The second is distribution, the kind Autodesk’s $200 million investment in World Labs buys by wiring a world model into software that designers already use. And the third, the rarest, is demonstrated reliability. In a field where everyone can show a demo and the proof says the dominant approach drifts, a company that can actually show its model staying accurate over long horizons under perturbation holds something almost no one else has. The two tests are both a way to read the technology and a map of where the defensible value sits, because long-horizon reliability is the asset that the boundary makes scarce. Every one of these strategies, though, runs into the same technical wall, the one this piece has been circling and now has to face directly: even a model that builds a good map watches it drift as it runs. That is the second test.
The second test, why a model that is right once drifts wrong
A world model exists to be run forward. You do not build one to describe a single frozen instant. You build it so a machine can ask what happens next, and then what happens after that, and then after that, hundreds or thousands of steps deep, so it can plan a route, a maneuver, a sequence of actions before committing to any of them. The whole value is in the rollout.
Which means the second test is the one that decides everything. The first test asks whether the map matches the world at a single moment. The second test asks whether the map stays matched as you travel across it. A world model can pass the first and fail the second, and when it does, it is worse than useless, because it looks trustworthy right up until the moment it quietly stops being trustworthy.
How a small error becomes a large one
The mechanism is the most important part here, and it is simple enough to hold in your head.
A world model rolls forward by feeding its own prediction back in as the starting point for the next prediction. Predict the next state, then treat that prediction as the new present and predict again, and again. The output of each step is the input to the next. This loop is what lets the model run far into the future and also makes errors dangerous.
Suppose the model is slightly wrong at each step. If the error were random, pointing a different direction each time, it would partly cancel out as you went, and the rollout would stay close to course. But the bias identified in the proof is systematic, not random noise. It comes from the model’s representation being bent the same way every time, because the bend is baked into the objective the model was trained on. So the error points in the same direction at every step, and instead of canceling, it accumulates. The model starts each step from an already-wrong state and adds the same wrong nudge on top. A small systematic bias, reapplied a few hundred times, does not stay small. It marches the prediction steadily away from the truth until the rollout is describing a world that does not exist.
Contrast that with a one-time error. If you measure the starting position slightly wrong but the model’s dynamics are true, that single error just rides along, constant, and the rollout stays parallel to reality. The thing that destroys long-horizon prediction is not a one-time mistake. It is a systematic bias that re-enters the loop at every step. And a biased representation is exactly a systematic bias that re-enters the loop at every step. This is why the bend in the map from the bell-curve chapter, tolerable at a single instant, becomes fatal over a long rollout. The first and second tests are linked: a failure of identifiability is the seed, and temporal drift is the harvest.
Put numbers on it to feel the difference. Imagine a model that is wrong by just one percent at each step, and imagine the error is systematic, always nudging in the same direction. After one step, you are off by one percent, which is nothing. The next step starts from that already-wrong state and adds its own one percent, and the step after that does the same. The errors stack, and because each one builds on a foundation the last one tilted, they stack faster than simple addition. A one-percent-per-step bias does not leave you one percent wrong after a hundred steps. It leaves you unrecognizably wrong, the prediction and the reality having parted company somewhere in the middle, even though the model was never more than one percent wrong on any single step it took. A model can be 99 percent accurate at every step and useless over a long horizon, and that sentence is the whole reason the second test exists.
Think of it as walking a straight line while a faint, constant crosswind pushes you sideways. On any single step, the wind barely moves you, a fraction of an inch, not worth correcting for. Walk a mile, and you are standing in a different field, because every step inherits the drift of the step before and adds a little of its own. The crosswind is the systematic bias. The mile is the rollout. And you never feel the moment it goes wrong, because at every single step, you were almost exactly on course.
Why a great next-frame score hides the problem
This also explains a trap that has misled many people, including some who should know better.
The natural way to measure a world model is to check how well it predicts the next frame. It is easy to measure, and it produces impressive numbers because predicting one step ahead is what these models are best at. The problem is that a model can have an excellent next-frame score and still drift badly over a long rollout because compounding errors differ from the errors that show up one step at a time. A tiny systematic bias is nearly invisible in a one-step test and devastating over a thousand steps. Scoring the next frame measures the wrong thing. It measures the part of the model that works and stays silent about the part that fails.
The benchmark that made it concrete
This is where the second of the spring’s two papers comes in, the empirical companion to the proof. In May, a team led by Lucas Maes of Mila and the Université de Montréal, with Yann LeCun and Randall Balestriero among the authors, released stable-worldmodel, an open platform for testing world models, on arXiv. It was built, in part, out of frustration: the field had become so fragmented that, as the paper notes, one commonly used planning algorithm had been independently reimplemented in at least five separate papers, a recipe for hidden bugs and results nobody could compare. The platform provides everyone with a shared set of environments and a way to apply controlled perturbations and observe what breaks.
What it found is the empirical face of everything above. On a standard task that asks a model to push an object into a target position, one tested model succeeded about 50 percent of the time under clean conditions, then dropped to about 12 percent when the agent’s color was changed, and to about 6 percent when the background color shifted. A color. Not a change in the physics, not a new task, a different shade of the same scene, and planning performance fell by most of its value. When the researchers added visual distractors, the planning success rate declined quadratically, holding across all baselines they tested. The paper’s own summary is blunt: current world models remain brittle outside their training distribution, with even modest shifts producing substantial degradation in planning.
The deepest finding is the one that ties the whole piece together. The models that planned worst were not always the ones that predicted worst. A model could forecast the next frame accurately and still plan badly, because it had learned to lean on irrelevant visual features, the color of the agent, the texture of the background, rather than the actual geometry of the task. That is the scrambled map from the identifiability chapter, caught in the act. The model latched onto a convenient shortcut that worked on the training data and had nothing to do with the real structure of the problem, and the moment the shortcut was disturbed, the model fell apart. Prediction accuracy proved a poor proxy for planning ability, which is to say that passing the easy first-glance test told you almost nothing about whether the model had built a real map.
The caveat: some drift is physics, not a flaw
Now I have to be fair to the models, because there is a kind of drift that no architecture can ever fix, and any treatment of this has to say so plainly.
Some systems are chaotic. The weather is the famous one, and the story of how we learned it is worth telling, because it draws the line between the drift a model causes, and the drift reality causes more sharply than any definition.
In 1961, a meteorologist at MIT named Edward Lorenz was running a weather simulation on an early computer. He wanted to extend a run he had already done, so rather than start over, he typed in the numbers from a printout of the earlier run as his new starting point. The machine had stored those numbers to six decimal places but printed only three, so where the computer had held .506127, Lorenz typed .506. A difference of one part in a few thousand, the kind of rounding any sane person would call negligible. He set it running and went for coffee. When he came back, the new run had diverged so completely from the old one that after simulated weeks, the two were unrecognizable. A change he could barely see in the fourth decimal place had rewritten the whole forecast. He published the finding in 1963, and it became the foundation of chaos theory.
That is what chaos means. In a chaotic system, two starting points that differ by an immeasurably small amount diverge exponentially quickly, so that after enough time their futures are completely unrelated. The difference does not stay small and ride along. It doubles, and doubles again, and the doubling is built into the equations. This is the real content of the phrase everyone knows, the butterfly effect: not that small things matter in some vague poetic sense, but that in a chaotic system the smallest imaginable difference in the starting conditions grows, on its own, into a total difference in the outcome. The mathematician’s name for the rate of this growth is the Lyapunov exponent, and when it is positive, prediction has a horizon beyond which the future is genuinely unknowable, no matter how perfect your model is, because no measurement of the present is infinitely precise and any imprecision at all explodes.
So for chaotic systems, even a flawless world model drifts, because reality itself amplifies the smallest uncertainty until the forecast and the world part ways. This is why your weather app is good for three days and useless for thirty. The atmosphere itself is chaotic, and chaos sets a hard ceiling on prediction that no better model can lift. No architecture beats this. It would be dishonest to suggest any could, and it would be a mistake to read the drift in these systems as entirely the model’s fault.
This is exactly why the distinction matters. There are two sources of drift, and they are different in kind. One is the unavoidable drift of chaos, set by physics, suffered equally by every possible model. The other is the avoidable drift of a biased representation, the systematic error that re-enters the loop because the model’s map is bent, which is a property of how the model was built and not of the world. The first kind is a law. The second kind is a choice of architecture. The whole open question this piece is building toward is about the second kind, the avoidable kind, for the large universe of systems that are not chaotic, where today’s statistical models drift because their own representation bends, rather than because reality forces it. Keep the two kinds separate as we go, because even an architecture that removes the avoidable drift entirely still meets the chaos floor at full force. No design beats the first kind. The contest is entirely over the second.
Where the drift actually bites
How much any of this matters depends entirely on what you are using the model for, and it is worth being concrete, because the stakes are wildly uneven across the field.
In autonomous driving, the rollout is the plan. A driving model imagines the next several seconds, the gap closing with the car ahead, the pedestrian stepping off the curb, the lane change, and acts on that imagined future. If the model drifts after two seconds of rollout, it is planning against a world that is already diverging from the real one, and the cost of being wrong is measured in lives. This is the highest-stakes case, and it is exactly where a few-minute or few-second consistency ceiling is a hard limit on what the model can be trusted to do.
In robotics, drift is the dropped part, the missed grasp, the arm that swings into something that was not where the model thought it would be. The economic cost is real, and the safety cost can be too, especially as robots move out of cages and into shared space with people. A robot planning a long manipulation sequence against a drifting model is rehearsing against a fiction.
In scientific and engineering simulation, drift is wrong physics, and wrong physics is a wrong answer. If you are using a world model to simulate how a material fatigues, how a fluid flows through a system, how a structure responds to load, a model that drifts gives you a confident, detailed, useless result. The whole point of the simulation was to trust it instead of building the physical thing, and a drifting model quietly forfeits that trust.
And then, at the other end, there is content. If a generated video drifts, the worst that happens is that it looks a little strange, a hand with too many fingers, an object that morphs when you are not looking. The stakes are aesthetic. This is why the pixel predictors and renderers can be genuinely excellent products while failing the second test badly: for the job they actually do, failing the second test does not cost much. The consistency a world model needs scales with the cost of being wrong, and the domains where world models are most economically exciting, driving, robotics, and industrial simulation, are exactly the domains where the cost of being wrong is highest and the second test matters most.
Both tests, one picture
Here is where the two tests leave us, because the next part is the open question they raise.
The pixel predictor fails the first test at the root because the variables that drive a physical system are often invisible in its pixels, and a model cannot recover what it never saw. The latent predictor can pass the first test in a Gaussian, spring-like world but fail it elsewhere, carrying a systematic bias that, during forward rollout, becomes drift. The transformer model inherits the same bias from the learned representation it attends to, with attention pushing the horizon out but not removing the ceiling, which is why the most capable interactive world model in the world holds together for a few minutes rather than forever. And underneath all of it, for chaotic systems, sits a floor of unavoidable drift that no model escapes.
So the summary of the state of the art is this. For the large and valuable class of physical systems that are not chaotic, today’s statistical world models drift over long horizons because of a bias they cannot train away, a bias that traces directly to the Gaussian assumption the leading proof identified. The capital is betting that this is a temporary limitation. The proof says that, for the dominant architecture, it is structural. Which raises the question the rest of this piece exists to frame: is this drift a property of all world models, or only of the statistical kind, and what is anyone actually doing about it?
The ways out people are trying
If the dominant statistical approach has a boundary, the obvious question is what lies beyond it. The field is not standing still, and there is a serious body of work, most of it older than the current funding wave, aimed squarely at building models whose maps stay matched to the world. None of it has yet produced a general world model that passes both tests for arbitrary non-chaotic systems, which is exactly why this is an open frontier rather than a solved problem. But the directions are real, and understanding them is the difference between hearing a pitch and judging one.
They sort into a few families, and the families share a single idea: if pure statistical learning bends the map, then putting some real structure into the model, structure that comes from physics rather than from data, can keep it straight.
Teach the model the physics it is supposed to obey
The most direct approach keeps the flexible neural network but adds a penalty whenever it violates a known physical law. These are physics-informed neural networks, introduced by Raissi, Perdikaris, and Karniadakis in 2019, and the idea is clean. If you know the equation that governs a system, a law of motion, a conservation law, or a heat equation, you can score the model on how well it matches the data and respects the equation, and train it to do both. The model is rewarded for being physically lawful, so it is pulled toward solutions that obey the physics rather than merely fit the observations.
This works genuinely well when you know the governing equation and the system is reasonably clean, and it has become a staple of scientific computing. Its limits are the conditions it needs. You have to know the equation, which rules out the many systems whose laws are unknown or only partly known. And the physics enters as a soft penalty, a pull rather than a guarantee, so the model can still violate the law when the data pushes hard enough. It bends the map back toward the truth without forcing it to stay there.
Build the physics into the shape of the model
A stronger version does not penalize violations after the fact but makes them impossible by construction, by building the law into the architecture so the model cannot break it. The clearest examples come from classical mechanics. Hamiltonian neural networks, introduced by Greydanus, Dzamba, and Yosinski in 2019, and the closely related Lagrangian neural networks from Cranmer and colleagues in 2020, are built so that the conserved quantities of physics, energy and momentum, are preserved automatically. The network is shaped to respect the deep structure of mechanics, so a model of a swinging pendulum cannot invent or destroy energy, because the architecture forbids it.
The related idea of neural ordinary differential equations, introduced by Chen and colleagues in 2018, treats the model as a continuous flow rather than a sequence of discrete jumps, which aligns with how physical systems actually evolve and tends to produce smoother, more faithful long-range behavior. The power of this family is that the structure is exact, a constraint the model cannot escape, rather than a penalty it can outweigh. The limit is that the structure has to apply. Energy-conserving architectures assume an energy-conserving system, and many real systems are dissipative, driven, or open, losing energy to friction, taking in energy from outside, or exchanging matter with their surroundings. The structure that guarantees fidelity for a frictionless pendulum is the wrong structure for a system with friction, and choosing the right structure means knowing the physics in advance.
Find the hidden equation in the data
A third family aims higher: instead of fitting a black box, have the machine discover the actual equation behind the data, the compact symbolic law that a physicist would recognize and write down. Data-driven discovery of governing equations, developed by Brunton, Proctor, and Kutz and their collaborators, searches for the sparse mathematical expression that best explains a system’s behavior. Symbolic regression methods, including the AI Feynman work by Udrescu and Tegmark in 2020, advance the idea of rediscovering physical laws from raw measurements. When this succeeds, the result is the best possible world model, the real equation, which by construction matches the world and does not drift, because it is the law itself rather than an approximation of it.
The catch is that finding the equation is extraordinarily hard. The space of possible expressions is enormous, the search is brittle in the presence of noise, and the methods struggle with high-dimensional systems, with partial observations, and with the messy, many-variable reality that world models are meant to handle. Equation discovery shines on clean, low-dimensional problems and strains badly as systems get as complicated as those the funded companies are targeting.
Combine the learned and the structured
A fourth family accepts that neither pure learning nor pure structure is enough on its own and tries to combine them: learned components for parts of the world that resist clean description, and structured or symbolic components for parts that obey known rules. This is the neurosymbolic and hybrid-modeling direction, and its appeal is obvious: use the flexible learner where the world is messy and the exact structure where the world is lawful, and get the strengths of both.
The difficulty is the seam. Joining a learned component to a structured one in a way that is stable, trainable, and that actually preserves the guarantees of the structured part is an unsolved engineering problem, and a hybrid wired together carelessly can inherit the weaknesses of both halves rather than their strengths. The promise is real, and the integration is the hard part, which is why hybrid approaches are an active area of research rather than a finished product.
Fix it on the data side
There is one more direction worth naming, because it follows directly from the companion theory to the proof. If the trouble is that a model’s representation leaves the regime where identifiability holds, one response is to change the data rather than the model. The theory accompanying the brittleness benchmark suggests that goal-directed training data does not explore the world broadly enough to keep representations identifiable, because an agent pursuing a narrow objective only ever sees a narrow slice of the state space. The fix would be to collect broader, more diverse data, or to have the agent actively explore to cover the space the guarantees require.
This helps at the margin and runs into two walls. Broader data does not remove a bias that is built into the training objective; the Gaussian assumption is still there no matter how much you explore, and active exploration in the real world is expensive and sometimes dangerous, which is the very reason world models exist in the first place. You cannot safely explore every near-crash to teach a car about near-crashes. Better data improves a statistical model. It does not change what the architecture can fundamentally represent.
Drop the learned model entirely
The most radical direction is to stop trying to fix the learner and remove it from the loop. Every approach above keeps a learned model and adds structure to it: a penalty, a conserved quantity, a discovered equation, a symbolic partner, broader data. The last direction asks what happens if, for the parts of the world whose laws you already know, you skip the learning step and run the law itself. Represent the state as real physical variables and compute the next state by directly executing the governing equation. There is no learned approximation to carry a bias, because there is no learned approximation at all. This is the symbolic, physics-grounded route, and in full disclosure, it is the direction my own work takes, so weigh what I say about it accordingly.
Its limitation is the sharpest of any approach here, and also the most straightforward. It only works where you can write the law down. For a domain whose governing physics is known and expressible, structural mechanics, heat transfer, electromagnetics, fluid systems, this route can sidestep the Gaussian boundary completely, and the chapter on the open question lays out exactly what that buys and what it is proven to do. For a domain whose rules are genuinely unknown, it has nothing to offer on its own, which is why it complements rather than replaces the learning approaches in the messy, lawless parts of the world. And like every approach, it still meets the chaos floor, because executing a chaotic law forward is still chaotic.
What the survey adds up to
Step back, and a pattern is visible across all of these. Every approach beyond pure statistical learning works by importing structure that does not come from the data, the known equation, the conservation law, the symbolic form, or the explicit constraint. Each one trades some of the flexibility that made neural networks attractive for some of the fidelity that physics provides, and each one buys real ground in exchange. And each one, so far, works best in the conditions it was designed for and strains outside them, which is why none has yet delivered a single general world model that passes both tests across the broad range of non-chaotic physical systems the funded companies are chasing.
That is the state of the frontier. The boundary the proof drew is real, the directions past it are real, and the question of whether any of them, or some combination, produces a general world model that both matches the world and holds together over time is one the final part returns to, with my own position and my own stake declared. A question has been lurking under all of it, though, and the next part faces it first: how would anyone even know if one of these approaches worked? That is a question about measurement.
How you measure a world model
You cannot tell whether a world model understands the world by watching its demo. The demo was chosen by the people selling it; it runs on the kind of input the model was trained on, and it lasts a few seconds. To learn what a model actually grasps, you have to test it the way you would test a suspicious witness, with cases built to catch it out. The field has started building those tests, and what they reveal is sobering.
Borrowing the test we use on babies
There is an elegant trick for measuring what a creature understands about physics before it can explain itself, and developmental psychologists invented it for infants. You show the creature something impossible, an object that passes through a solid wall, a ball that vanishes when a screen lifts, and you measure surprise, because a baby that understands solidity will stare longer at a ball that went through a wall. The method is called violation of expectation, and it works because surprise reveals an expectation, and an expectation reveals an internal model.
Meta borrowed this exact paradigm to test world models. It’s the IntPhys 2 benchmark, released in 2025, which shows a model with pairs of videos that are identical except that one obeys physics and the other breaks it, and asks whether the model can tell which is which. The benchmark targets four principles that human children grasp early: permanence, that objects do not wink out of existence; immutability, that an object does not change into a different object; spatio-temporal continuity, that things move along connected paths rather than teleporting; and solidity, that two solid objects do not pass through each other. These are the bedrock intuitions of physical reality, the things a two-year-old already knows.
The result that should give everyone pause
Here is what the test found. Humans score between 85 and 95 percent. The best models, including Meta’s own V-JEPA 2, perform near chance, around 50 percent, on the harder scenes. The most advanced world models in the world, trained on millions of hours of video, still fail at the intuitive physics a toddler has mastered. They can produce gorgeous, fluent video of a ball bouncing, and they cannot reliably tell you that a ball passing through a wall is impossible. That is the gap between looking right and understanding, measured directly, and it is wide.
A family of tests, because there is more than one thing to measure
V-JEPA 2 is worth pausing on because it is a serious system and its evaluation is instructive. It is a 1.2-billion-parameter world model built on the JEPA architecture, trained on more than a million hours of video, and capable of zero-shot planning and robot control in environments it was not trained on. Alongside it, Meta released three benchmarks because there is more than one ability worth testing. IntPhys 2 checks whether a model knows what is physically possible. Minimal Video Pairs checks whether it grasps cause and effect by showing it near-identical clips that differ in one causal detail. And CausalVQA checks whether it can answer counterfactual questions, the what-would-have-happened-if reasoning that real understanding requires. Separately, the stable-worldmodel platform from earlier measures a fourth thing entirely: whether any of that understanding survives contact with a planning task under perturbation.
Prediction, understanding, and planning are three different things
Put those tests together, and they make a point that cuts through most of the marketing in this field. Predicting the next frame, understanding the physics, and planning a task are three separate abilities, and a model can be good at one while failing the others. It can forecast the next frame beautifully, assess the likelihood that an event is physically possible, and collapse on a planning task the moment you change a color. Each benchmark probes a different facet, and a high score on the easy, eye-catching one, next-frame fidelity, tells you almost nothing about the hard, load-bearing ones. A buyer who is shown a crisp demo and infers understanding, or infers planning ability, is making a leap the evidence does not support.
What good evaluation looks like
The lesson for anyone evaluating a world model follows directly. A demo is cherry-picked, in-distribution, short, and unperturbed, making it nearly worthless as evidence of understanding. Good evaluation is the opposite on every axis: adversarial, built to surface what the model gets wrong rather than to flatter it; out-of-distribution, applying the kind of perturbation the real world will; long-horizon, testing the full rollout rather than a single step; planning-oriented, measuring whether the model helps an agent act rather than only predict; and standardized, so that results from different models can actually be compared. The field is building these instruments, IntPhys 2 and the stable-worldmodel platform among them, and they are not yet the universal standards that procurement officers and regulators will eventually need. The gap between what a world model can demonstrate and what it actually understands is measurable, and measuring it is the only protection a buyer has. Which makes that gap a question of trust, and trust is where deployment, safety, and governance come in.
What happens when these models leave the demo
A world model in a research paper that drifts is a curiosity. A world model in a car, a surgical robot, or a power plant that drifts is a hazard. As the capital pushes these systems out of the lab and into deployment, the boundary ceases to be an academic question and becomes one of safety, governance, and accountability when the map is wrong.
Confidently wrong is the dangerous failure
The most useful way to think about the risk is to notice what kind of error the drift produces. A model that knows it is uncertain can flag it, slow down, ask for help, or hand control back to a person. The failure mode we have been describing is different and worse: a world model that has drifted is confidently wrong. It rolls forward, producing a smooth, plausible, internally consistent picture of a future that does not match reality, and it gives no signal that anything is off. In a content tool that produces a strange-looking video. In a system steering a two-ton car through traffic, confidently wrong is the property that kills people, because the model commits to a plan built on a future that never will.
This is why the brittleness result matters beyond the benchmark. A model that scores well on its demo and then collapses under a color shift hides its failures until they turn catastrophic, which is precisely the profile that safety engineering exists to rule out. The gap between how a world model looks in a controlled demo and how it behaves under the messy distribution of the real world is, in safety-critical settings, the whole ballgame.
Evaluation is a governance problem
If a model can look flawless and be fragile, then the only protection a buyer, a regulator, or a court has is measurement, and the field’s measurement is not yet up to the job. The same fragmentation that motivated the stable-worldmodel benchmark, where a single planning method had been reimplemented five different ways with no common standard, means there is no agreed, trusted way to certify that a given world model is reliable over long horizons under realistic perturbation. That is an engineering inconvenience inside a lab. Outside the lab, where these systems are being sold into cars, factories, and hospitals, the absence of a standard is a governance crator. You cannot regulate, insure, or safely procure what you cannot measure, and right now, the measurement that would separate a safe world model from a dangerous one is exactly the measurement the field has not standardized.
The builders are aware of the stakes. When DeepMind released Genie 3, it noted that the model’s open-ended, real-time generation introduced new challenges for safety and responsibility and that it had worked with a dedicated responsibility team. That is the right instinct, and it also signals how immature the governance is: the safeguards are being invented company by company, alongside the technology, rather than resting on any shared standard of what a trustworthy world model must demonstrate.
The systemic risk of a word that means too much
There is a second-order risk that an investor, in particular, should keep in view. When a term inflates the way AMI’s own CEO predicted “world model” would, capital flows toward the label, and the label has detached from any guarantee of long-horizon reliability. That sets up a familiar pattern: money chases a category faster than the category’s fundamentals are verified, and the correction, when reliability is finally tested in the field, can be sharp. The gap between the funding and the proof is an opportunity for a careful investor and, at the same time, a source of systemic fragility for the category, because a few high-profile failures of confidently wrong models in safety-critical settings would re-rate the whole field at once.
None of this is an argument against world models. It is an argument for treating long-horizon reliability as a safety property rather than a performance metric, for demanding standardized evaluation before deployment rather than after an incident, and for keeping a person in the loop wherever a drifting model could do real harm. The technology is moving toward exactly the high-stakes settings where these disciplines matter most, which means the gap between what these models can demonstrate and what they can be trusted to do is the gap that responsible builders, buyers, and regulators have to close. That gap is, once more, the open question. Before facing it head-on, it helps to watch every piece of this argument operate on a single scene, so that is where we go next.
One example, all the way through
The argument so far has moved through many pieces: two tests, three machines, a bell curve, a proof, a benchmark, and a drift. It helps to watch them all operate on a single concrete case, from start to finish. So take one scenario, an ordinary one, and run it through everything.
A self-driving car approaches a four-way intersection. A child is standing on the corner holding a ball. The car has a world model whose job is to predict what happens next and plan accordingly. Watch what each part of this piece says about that moment.
The first test, at the intersection
The car’s cameras produce a flood of pixels, millions of numbers a second. The world model compresses them into a latent state, its internal summary of the scene. The first test asks whether that summary recovered the real structure or a blue-cover shortcut.
The real structure is a short list of factors that drive what happens next: the child’s position and velocity, the ball’s position and velocity, and the fact that a ball near a child is often chased. A model with identifiability has those as clean, separate variables it can reason about. A model without it could have learned something like “small figure plus round object, usually stationary at corners,” a summary that fit its training footage, where children at corners mostly stayed put, and that has no clean variable for the ball rolling into the street with the child after it. Both summaries looked fine on the training data. Only one of them can answer the question that matters.
Now layer in the machine. If this is a pixel model, it faces causal blindness: it cannot see the child’s intent, which is the variable that decides everything, and intent is exactly the kind of hidden driver no camera records. If it is a latent or transformer model, it can build a representation of the scene’s structure, which is better, and it inherits the bell-curve boundary, which is where the next part of the story comes in.
This is not a marble-in-a-bowl world
The proof says the latent model recovers the truth only if the scene is Gaussian and mean-reverting. Is it? A child chasing a ball into the road is the opposite of mean-reverting. There is no central resting value the child relaxes back toward. It is a sudden, one-directional departure, a dart into the street, the kind of rare extreme event that lives in the heavy tail, not the fat middle, of the distribution. It is also the single most important event the car will ever need to predict.
So this is precisely the case the bell-curve assumption handles worst. The model’s training objective pulled its representation toward a Gaussian shape, where darting children are vanishingly rare, and the real distribution of what children near roads do has a heavy tail where darting, while uncommon, is common enough to be the whole reason you drive carefully past a school. The model carries a systematic bias that underweights the extreme, and the extreme is what kills.
The second test, over the next two seconds
The car does not need one prediction. It needs to roll the scene forward two or three seconds and plan against the whole trajectory. This is where drift enters. If the model’s representation is biased, that bias re-enters the loop at every step of the rollout, so the crosswind on the straight-line walk and the predicted trajectory bend steadily away from what the child will actually do. The model predicts the child staying put for two seconds, each frame only slightly wrong, the error compounding, until the planned path is built around a child who, in the model’s imagined world, never moved, while the real child is already in the street.
And the brittleness benchmark warns of one more thing. Suppose the model was trained mostly on daylight footage and this is dusk, or the child’s coat is a color that the training data is underrepresented in. The benchmark showed planning success falling from about half to single digits under exactly this kind of shift, and worse, that a model can predict the next frame well while planning badly, because it latched onto the wrong features. A model that aces its demo in daylight can fail at dusk, and give no warning that it has.
What the failure looks like, and why it is the dangerous kind
Here is the part that ties to deployment. When this model fails, it does not throw an error or flash a warning light. It produces a smooth, confident, internally consistent prediction of a future in which the child stays on the corner, and it plans a clean path through the intersection accordingly. Confidently wrong. The car commits to a plan built on a future that was never going to happen, and the cost of that particular error is not measured in dollars.
This is why the consistency a world model needs scales with the cost of being wrong, and why the same drift that is a charming quirk in a generated video is a fatal flaw in a car. The intersection is the whole piece in one scene: a model that may have built a decent map, carrying a bias from an assumption the moment violates, drifting over the rollout that matters most, failing silently under a shift it never trained on, in exactly the high-stakes setting where the funded companies most want to deploy.
And the open question, right here
So does the car’s model have to fail this way? For the genuinely chaotic part of the scene, some unpredictability is real, and no model escapes it; a child is not a deterministic system, and perfect prediction was never on offer. But most of what the car needs is not chaotic. A ball rolls into a street by ordinary mechanics. A child accelerates by ordinary biomechanics. These are lawful, predictable things, and the drift the model suffers on them traces to the statistical approach and its bell-curve assumption, not to any law of nature. Whether a different kind of world model could hold that trajectory steady while the statistical one drifts is an open question, and at that intersection, it stops being academic. That is where the piece turns next.
The open question, and how to read any world-model claim
Here is the question the whole piece has been walking toward, stated as plainly as I can.
The proof drew a line around the statistical approach. For a Gaussian, spring-like world, the leading architecture recovers the truth; outside that world, it carries a bias it cannot train away, and that bias becomes drift over a long rollout. The research directions in the last part are all attempts to get past that line, and none has yet produced a general world model that clears both tests for the broad range of systems the field cares about.
So the field does not yet know the answer to a basic question:
Is the drift a property of all world models, a law as deep as the chaos floor, or is it a property of the statistical way of building them, an artifact of one approach that a different approach could avoid?
That is a real question, the one the next few years of this field will answer, and a great deal of capital is riding on the answer being the optimistic one, that the limit is a feature of today’s methods and not of world models as such.
Our answer, and the stake behind it
I have a view on this, and a stake in it. My co-author and co-founder, Łukasz Chmiel, has a preprint up on the arXiv from ARYA Labs that provides an answer—Identifiability Without Gaussianity: Symbolic World Models and Near-Infinite Temporal Consistency. Here is what we found.

We prove that the boundary is a property of the statistical alignment mechanism and that an architecture built on a different foundation steps around it. A statistical world model learns a compressed picture of the world from data, and that learning is what bakes in the bell-curve assumption and, with it, the bias that drifts. The architecture in our paper, which we call a physics-grounded symbolic architecture, does not learn a picture of the world at all. It represents the state of a system as the actual physical quantities that govern it, position, velocity, temperature, stress, field strength, and it computes the next state by running the governing equation forward, executing the law itself. The map is the law. Because no learned approximation sits between the model and the physics, there is no Gaussian assumption to bake in and no systematic bias to compound. We prove that such an architecture recovers the true variables of the world exactly for any distribution, without any bell-curve condition. Identifiability without the bell curve.
Then we prove what that buys over a long rollout, which is the property that matters. With no representation bias to re-enter the loop, the only error a physics-grounded model makes at each step is the rounding error any computer makes when it stores a number, around one part in ten thousand trillion. That error is so small and so free of the systematic drift that destroys statistical models that predictions stay accurate for an effectively unbounded number of steps. We put a number on the gap. For a strongly aligned statistical model on a conservative physical system, the point where error breaches a fixed tolerance shifts from a few hundred or a few thousand steps to of order ten trillion steps, a factor of about 4.5 times ten to the thirteenth power. We call the property near-infinite temporal consistency, and the name is literal in a precise sense: the horizon is set by the precision of the arithmetic, and no longer by a flaw in the model’s picture of the world. The crosswind from the drift chapter is simply gone, because there is no biased map for it to blow against.
Why have a machine check the math?
There is a reason to take these as more than the usual confident claims, and it is worth explaining, because it is rare in this field. The core theorems are proved on paper and then formalized in a system called Lean 4, and that second step carries real weight.
A proof written the ordinary way is checked by human reviewers. They are skilled, and they are also fallible, and over the course of a long mathematical argument, a reviewer can miss a hidden assumption, an unjustified leap, a step that looks fine but is not. A proof written in Lean is instead checked by a computer that mechanically verifies every single logical step against the axioms of mathematics and rejects the proof if even one step is unjustified or an assumption is smuggled in. Lean even gives the mathematician a keyword, written sorry, that lets you mark a step you have not actually finished and move on; a proof that still contains a sorry ha” has a hole in it. Our formalized theorems contain no sorry. The machine confirmed every step, leaving no holes open.
Put plainly, it is the difference between a mathematician telling you the result is correct and a proof assistant mechanically certifying that it is, with no gaps it was willing to overlook. In a field where most claims rest on benchmarks that, as we saw, can collapse under a change of color, a machine-checked proof is a different and sturdier kind of evidence. What it certifies is narrow and real: the specific mathematical claims we make about the architecture are true. It says nothing about whether the architecture is the best way to build a world model.
The theory explains a result someone else measured
A proof tells you a claim is internally true. It does not, on its own, tell you that the claim describes the real world. So here is the other reason to take this seriously: the theory explains an experiment we did not run, that someone else already published, and that landed before our paper.
Recall the brittleness benchmark from the measurement chapter, the one from Maes, LeCun, and Balestriero, the same Balestriero and LeCun who co-wrote the proof that opened this story. It found two things about statistical world models. They collapse under a trivial perturbation, planning to fall from about half to single digits when a color changes. And prediction accuracy is a poor proxy for planning: a model can forecast the next frame well while planning badly. Those were empirical findings, measured, with no theory attached to explain why.
Our framework predicts both from a single cause. The prediction-planning gap is the statistical ceiling in motion: a representation can be almost perfect one step ahead, which is what a next-frame score measures, while carrying the systematic bias that compounds over a rollout, which is what wrecks planning. The two scores come apart exactly as the theory says they must. And the collapse under a color change is the identifiability failure made visible: a statistically aligned representation latched onto whatever features were convenient in training rather than the causal structure of the task, so a change that means nothing to the physics but everything to the statistics knocks the model out of the regime where it works. The benchmark measured the symptom. The theory names the disease.
Be precise about what this does and does not show, because the distinction matters. The benchmark tested statistical models, so it corroborates our account of why they drift, the diagnosis, and not the positive claims about the physics-grounded alternative, which rest on the proof. But a theory that both proves its case formally and explains an independent experiment run by the very researchers who drew the original boundary is standing on two legs rather than one. That is rarer than it sounds, and it is the main reason I trust the result as a statement about the world rather than the page.
What the paper does not claim
Two limits sit on all of this, and stating them is part of the case, not an exception to it. The first is that executing the law requires knowing the law. A physics-grounded model works for systems whose governing equations you can write down, covering an enormous amount of engineering and physical science, including structural mechanics, heat transfer, electromagnetics, and fluid systems, and excluding domains where the rules are genuinely unknown. The second is the chaos floor from the Drift chapter. Running the true law forward does not beat chaos, because chaos lives in the law itself; for a chaotic system, even an exact model diverges at the Lyapunov rate, and our horizon there collapses to the same physical limit everyone faces. The claim is precise and bounded. For the large class of non-chaotic systems whose physics can be expressed, we prove that the drift that has defined the statistical era can be crossed. The paper does not claim that symbolic architectures beat every possible future world model. It claims, and proves, that the boundary the field just drew can be crossed, and it shows one constructive way past it.
So that is our answer to the open question. The drift is a property of one specific way of building world models, and there is at least one other way to build them. You do not have to take my word for any of it, and you should not, which is exactly why the rest of this section hands you the questions to ask of any world-model claim, mine included.
How to read a world-model claim
The term is about to mean nothing, because the CEO of one of the best-funded world-model companies told you it would, and he was right about the incentive. When the label stops carrying information, you fall back on questions, and the two tests give you the questions that matter. Here is how to use them the next time someone puts a world model in front of you.
Begin with the second test, because it is the one the demos are built to hide. Ask how far the model stays accurate before it drifts, and insist on a number measured over a long rollout, not a single impressive next frame. Then ask what happens when you change something that should not matter, the color of an object, the lighting, a background, or a sensor the model was not trained on. The brittleness benchmark exists precisely because models that look flawless collapse under these trivial shifts, falling from half-success to single digits on a color change, and the only way to know whether the model in front of you is one of those is to perturb it and watch. A vendor who can show you accuracy that holds over a long horizon under perturbations is showing you something real. A vendor who can only show you a beautiful demo is showing you the part that always looks good.
Then turn to the first test and ask what the model is actually producing. Is it predicting observations, pixels for a human to look at, or is it recovering a faithful state that a program can compute on? The World Labs taxonomy gives you the clean version of this question: is it a renderer, a simulator, or a planner, and is that the one your job needs? A renderer that looks like a simulator will pass the demo and fail the deployment, because looking right and being structurally right are different things, and the gap between them is exactly where the money gets lost. Make the vendor tell you which machine they built.
Ask, next, where the structure comes from. Is the model learning the physics entirely from data, in which case the Gaussian boundary applies and you should ask how they handle systems that break it, or is real structure built into the model, in which case ask what structure it uses and whether it matches your system. This is the question that separates the approaches in the last part from the dominant statistical one, and a founder who can answer it crisply, who can tell you exactly what their model assumes about the world and where those assumptions hold, understands their own system in a way that diligence will reward.
Finally, ask what it costs to teach the model something new. When a new constraint, a new regime, or a new physical fact has to be incorporated, does the model absorb it, or does the whole thing have to be retrained from scratch? That retraining bill is a real line in the total cost of ownership, and it is also a tell: a model that can only learn by statistical exposure has to be re-exposed to everything, while a model with real structure can sometimes be told. The answer reveals what kind of machine you are buying.
Where this leaves an investor
The pattern underneath all four questions is the same. The capital has moved ahead of the math. A billion dollars went into world models in the same season; a proof drew a line under part of the field, and the gap between the funding and the fundamentals is what a careful investor is actually pricing. The durable bets will be the companies whose technical story survives the proof, the ones building toward long-horizon reliability in a specific physical domain where being right matters and staying right over time is the whole product. The fragile bets will be the ones whose value rests on a demo and a label, both of which next year will be stress-tested hard.
None of this requires you to know whether the optimistic or pessimistic answer is correct. It requires you to ask the questions that reveal which kind of company you are looking at, and to notice that most of the market is not yet asking them. That is the edge. The term is inflating; the proof and the benchmark are public; and the diligence that uses them is still rare.
Let’s Wrap This Up
Two things happened to world models this spring. A billion dollars said the next era of machine intelligence will be built on systems that carry a model of the world. A proof said that the leading way of building those systems recovers the world only when the world is shaped like a bell curve, which it almost never is, and drifts away from the truth the longer you run it.
Both of those things are true at once, and holding them together is the whole point. The bet is serious, the builders are serious, and the technology is genuinely moving. The boundary is also real, drawn in a primary source by the same researcher whose company raised the largest seed round in European history. The map these machines build is getting better fast. For most of the physical world, it still drifts as you travel across it, and whether that drift is a law of all world models or a limit of one way of building them is the question this spring put on the table.
My co-author and I put our answer on the table beside it, proven and machine-checked: the drift belongs to the statistical way of building world models, and for systems whose laws can be written down, there is a way of building them where it never starts. The field will now test that claim, which is exactly what should happen to a claim. The money, meanwhile, is betting that the question gets settled in its favor, and the evidence shows that, for today’s dominant architecture, it will not be settled by scale alone. Somewhere in that triangle is the future of this field, and it is being written right now, in benchmarks and proofs and a handful of architectures that are trying to build a map that does not drift. The next time someone offers you a world, ask how long it will remain standing after you start walking through it. The answer tells you whether you are being handed a map or a mirage.
Disclosure and disclaimer. The author, Dr. Seth Dobrin, is the founder of ARYA Labs and is a co-author of the arXiv paper whose results are presented in the final part of this piece. That section is the author’s own work and is presented as the case of an interested party, with the conflict of interest stated where the results appear. The views expressed are his own. Silicon Sands News is an independent publication. Nothing in this newsletter is investment, legal, or financial advice, and it should not be relied on as a basis for any investment decision. Companies and research referenced are cited to primary sources for the reader’s own evaluation. Each chart cites its sources in its footer, and the underlying data for every Datawrapper chart is downloadable directly from the chart.
A world model glossary
A reference for the terms that recur in any serious discussion of world models, in the order they tend to come up rather than alphabetically, so it reads as a refresher.
World model. A machine’s internal model of how an environment behaves, built so the system can predict how the environment will change and how its own actions will change it. The thing in your head that tells you a cup sliding off a table will fall and shatter before it happens.
Latent state, or latent. The compact internal summary a model squeezes its raw input down into. A million pixels become a few dozen numbers, and those numbers are the latent. The whole question of the first test is whether those numbers track the real drivers of the scene or a convenient shortcut.
Identifiability. The property of having recovered the true hidden variables of a system rather than a tangled stand-in. A model with it built a map whose features correspond to real-world features. The first of the two tests in this piece.
Up to a linear transformation. The fine print on identifiability. The model does not have to label its variables with nature’s exact names and units; it is allowed a clean, reversible rotation and rescaling of the whole coordinate system, the way a map is still perfect if it is rotated or printed at half scale. What it may not do is scramble the relationships.
Temporal consistency. Whether a model’s predictions stay accurate as it rolls forward step after step, or whether small errors compound into nonsense. The second of the two tests.
Drift. What happens when temporal consistency fails. A systematic error re-enters the prediction loop at every step and accumulates, so the rollout bends steadily away from reality even when every single step was nearly right.
Self-supervised learning. Teaching a model without hand-labeled answers by hiding part of the input and making it predict the hidden part from the rest. The engine behind both language models and world models.
Collapse. The cheat a self-supervised model is tempted into, making its internal summary identical for every input, which scores perfectly and learns nothing. Regularizers exist to prevent it.
Regularizer. A piece of the training objective that constrains what the model can learn, often to prevent collapse. The LeJEPA regularizer prevents collapse by pushing the model’s representations toward a bell-shaped curve, which is also the source of the boundary identified in the proof.
Gaussian (normal) distribution, or bell curve. The familiar symmetric distribution where values cluster near the average and extremes are vanishingly rare. Common as the shapes of noise and averages are, far less common is the shape of a physical system’s state over time.
Heavy tail. A distribution in which rare extreme events are far more common and far more consequential than a bell curve would predict. Wealth, earthquakes, market crashes, and turbulence all have heavy tails. Most interesting physical systems are more heavy-tailed than Gaussian.
Mean-reverting, or Ornstein-Uhlenbeck. A system that always drifts back toward a central resting value, like a marble in a bowl or a thermostat-controlled room. The gentle, self-correcting kind of motion the proof’s guarantee requires, and the kind most physical systems do not have.
Chaos and the Lyapunov exponent. A property of some systems, the weather above all, where tiny differences in starting conditions grow exponentially into completely different outcomes. The Lyapunov exponent measures how fast. Where it is positive, prediction has a hard horizon no model can beat, which is the one source of drift that is physics rather than a flaw.
JEPA, Joint-Embedding Predictive Architecture. Yann LeCun’s program for building world models that predict in the space of learned representations rather than raw pixels. The lineage runs through I-JEPA, V-JEPA, and LeJEPA, and it is the technical core of AMI Labs.
Autoregressive. Generating one piece at a time, each conditioned on everything before it, the way a language model writes word by word. Natural for sequences, prone to compounding error over long rollouts.
Diffusion. Generating by starting from pure noise and refining it step by step into a coherent result, the way a sculptor removes everything that is not the statue. Strong at high-fidelity detail and at representing many possible outcomes. The method behind Sora.
Tokenizer. The component that chops continuous input, like video, into the discrete chunks a transformer can work on. Doing this well, without throwing away what matters, is half the battle for a video world model.
Attention. The transformer’s signature operation, weighing every chunk of input against every other to capture long-range structure. It can extend how long a model stays coherent, but it only works with the chunks the tokenizer kept, so it pushes the horizon out without removing the ceiling.
Renderer, simulator, planner. World Labs’ functional taxonomy. A renderer outputs observations for human eyes and is judged on whether the picture looks right. A simulator outputs a faithful state that a program can compute on and must respect the laws of physics. A planner outputs actions. Different jobs, different failure modes, and worth knowing which one a vendor is selling.
Physics-grounded symbolic architecture, PGSA. A world model that represents the state of a system as its actual physical variables and computes the next state by directly executing the governing equation, with no learned approximation in the loop. The route taken in the author’s paper requires the governing law to be expressible, and for non-chaotic systems it removes the statistical drift entirely.
Formal verification and Lean 4. Proving a mathematical claim inside a proof assistant, a program that checks every logical step against the axioms of mathematics and rejects any gap. Lean 4 is the proof assistant used for the core theorems in the author’s paper; its sorry keyword marks an unfinished step, and a formalized proof with no sorry has been certified complete by the machine rather than trusted to human review.
Seth this is an extraordinary survey paper of a fast moving field. I read it May 25 paper and it was clear that this is a hard boundary to the abilities of the laten state world models based on statistics, but as you point out when you use physical and symbolic models of the world you can do much better and this is not necessarily a general solution and we don’t actually need a general solution. We need particular solutions for particular problems.
To put it differently, a very smart human, highly trained in physics with an extremely good memory perhaps a world class memory perhaps a once in a generation memory can solve a problem. Then that solution can be coded into a world model.