




Silicon Sands News, read across all 50 states in the US and 96 countries.
We are excited to present our latest editions on how responsible investment shapes AI's future, emphasizing the OECD AI Principles. We're not just investing in companies, we're investing in a vision where AI technologies are developed and deployed responsibly and ethically, benefiting all of humanity.
Our mission goes beyond mere profit— we are committed to changing the world through ethical innovation and strategic investments.
We're diving deep into a topic reshaping the landscape of technology and investment: "Faux-pen" Source… Do you understand the implications of using a restricted community license? Meta's Llama models Founders and Investors could lose big.
The Promise of Open-Source AI
In a recent post, Mark Zuckerberg made a compelling case for open-source AI, positioning Meta as a leader in this approach with the release of Llama 3. Zuckerberg asserts that "open source is necessary for a positive AI future," arguing that it will ensure more people have access to AI's benefits, prevent power concentration, and lead to safer and more evenly deployed AI technologies.
These are noble goals, and the potential benefits of truly open-source AI are significant. Open-source models could democratize access to cutting-edge AI capabilities, foster innovation across a broad ecosystem of companies and researchers, and potentially lead to more robust and secure systems through community scrutiny and improvement.
The Reality of Llama's License
The Llama 3 Community License Agreement reveals a series of critical, nuanced terms challenging traditional notions of open-source software. While Meta has taken significant steps towards making their AI technology more accessible, the license terms introduce several key restrictions, raising questions about whether Llama can be considered open source.
A clause limiting commercial use outside the norm for open-source projects is at the heart of these restrictions. The license stipulates that if a product or service using Llama exceeds 700 million monthly active users, a separate commercial agreement with Meta is required. While high enough to accommodate most startups and medium-sized businesses, this threshold significantly differs from the unrestricted commercial use typically allowed in open-source licenses. It effectively caps the scalability of Llama-based applications without further negotiation with Meta, potentially creating uncertainty for rapidly growing startups or enterprises contemplating large-scale deployments. It would certainly be a great problem to get to this cap. Still, at that point, Meta could hold you hostage as your product would likely depend significantly on the underlying model system(s).
Another concerning aspect of the license that deviates from open-source norms is the restriction on using Llama's outputs or results to improve other large language models, ‘except Llama 3 itself or its derivatives’. This clause has far-reaching implications for the AI research and development community and anyone using LLMs to develop other AI systems that are not direct derivatives of Llama– I know of several start-ups taking this approach. In essence. This provision creates a one-way street of innovation—while developers are free to build upon and improve Llama, they are barred from using insights gained from Llama to enhance other AI models. This restriction significantly hampers the collaborative and cross-pollinating nature of AI research and AI product development, which has been instrumental in driving rapid advancements in the field.
The license also includes provisions related to intellectual property that could potentially terminate a user's rights if they make certain IP claims against Meta. While it's not uncommon for software licenses to include some form of patent retaliation clause, the breadth and potential implications of this provision in the Llama license warrant careful consideration. In some scenarios, it could create a chilling effect on legitimate IP disputes or force companies to choose between using Llama and protecting their innovations.
These restrictions, taken together, create what we might term a "faux-pen source" model. This hybrid approach offers more accessibility than closed, proprietary systems but falls short of true open-source software's full openness and flexibility. This model presents a nuanced landscape for developers, startups, investors, and enterprises. It may create more risk for unweary founders and investors if they are not fully aware that the license is not really an open-source license.
The availability of Llama's model weights and the permission to use and modify them for a wide range of applications represents a significant step towards democratizing access to cutting-edge AI technology. It allows developers and researchers to examine, experiment with, and build upon a state-of-the-art language model without the immense computational resources typically required to train such models from scratch. This opens possibilities for innovation and application development that might otherwise be out of reach for smaller players in the AI space.
However, the license restrictions create a series of potential pitfalls and limitations that users must carefully consider. While likely irrelevant for most users in the short term, the commercial use restriction could become a significant issue for successful applications that achieve viral growth. It places a ceiling on the potential success of Llama-based applications unless the developers are willing and able to negotiate a separate agreement with Meta at a point when they are already heavily dependent on them and likely not in a good position for negotiation. This introduces an element of uncertainty that could make Llama less attractive for venture-backed startups or enterprises planning large-scale deployments.
The prohibition on using Llama's outputs to improve other models is even more consequential. It creates an artificial barrier in the AI ecosystem, potentially slowing down the overall pace of innovation. This restriction goes against the spirit of open collaboration that has been a driving force in AI advancements. It could lead to a fragmentation of the AI landscape, with Llama-based developments existing in a silo, unable to contribute to or benefit from advancements in other model architectures or implementations.
The intellectual property provisions add another layer of complexity. While designed to protect Meta's interests, they could have unintended consequences. Companies with significant IP portfolios in the AI space might hesitate to adopt Llama, fearing that it could compromise their ability to defend their intellectual property. This could limit Llama's adoption among precisely the kind of sophisticated users who might contribute valuable improvements or applications.
It's worth noting that Meta's approach with Llama is common. Other major tech companies have also released "open" versions of their AI models with various restrictions without claiming they are open source. However, Llama's license terms are particularly noteworthy given the strong rhetoric from Mark Zuckerberg and Meta's Chief AI Officer, Yann LeCun, around the importance of open-source AI. Meta is not known for being forthright in their intentions, which plays into that perception. However, assuming the Lama models are trained on Meta property data (e.g., Facebook and Instagram), it is unsurprising they have not shared that. The other restrictions seem unnecessary given that, at their admission, selling software is not their business. For Meta, these factors discount the discord between this rhetoric and the reality of the license terms, highlighting the challenges and complexities involved in balancing openness with commercial interests in the AI space that other players in the domain face.
Llama's "faux-pen source" nature also raises broader questions about the future of AI development and deployment. As AI becomes increasingly central to a wide range of applications and services, the terms under which these technologies are made available will have far-reaching implications. The Llama license represents an attempt to balance fostering innovation and maintaining some degree of control. Whether this approach will become a new norm in the industry or whether it will face pushback from developers and researchers advocating for truly open models remains to be seen.
For developers and companies considering Llama, carefully considering the long-term implications of the license terms is crucial. While the model offers impressive capabilities and industry-leading safeguards (I will discuss below) and the opportunity to work with cutting-edge AI technology, the restrictions could have significant implications depending on the project's specific use case and long-term goals. It may be necessary to weigh the benefits of Llama's accessibility and performance against the potential limitations on scalability and innovation.
While the release of Llama represents a step towards more open AI development, the reality of its license terms needs to be revised to true open-source principles. The "faux-pen source" model it represents offers increased accessibility compared to fully closed systems but comes with unnecessary strings attached that could limit its utility and appeal in certain scenarios. As the AI landscape continues to evolve, it will be crucial for developers, researchers, and policymakers to grapple with these nuanced approaches to AI licensing and their implications for innovation, competition, and the broader trajectory of AI development.
Data Transparency and Open-Sourcing
Meta's release of Llama 3 represents a significant step towards more accessible AI technology, with the model weights being made available under their community license. As discussed above, while laudable, this needs to include more than the full transparency that characterizes open-source AI initiatives. A critical component remains shrouded in mystery: the training data. This lack of openness regarding the data used to train Llama 3 raises concerns about scientific integrity, fairness, and ethical AI development.
Reproducibility, a cornerstone of scientific research, is at the forefront of these concerns. The ability to reproduce results is fundamental to the scientific method, allowing for verification, validation, and the building of consensus within the scientific community. However, with access to the training data used in Llama 3's development, it becomes virtually possible for researchers and scientists to fully replicate Meta's results or independently verify the model's properties.
Closely related to the issue of reproducibility is the challenge of conducting comprehensive bias and fairness assessments. Large language models, by their very nature, have the potential to perpetuate or even amplify societal biases present in their training data. With the ability to examine the data that shaped Llama 3's understanding and outputs, independent researchers can easily assess potential biases or fairness issues within the model.
The opacity surrounding the data collection, cleaning, and curation processes further compounds these issues. These processes play a crucial role in shaping a model's behavior and outputs, yet in the case of Llama 3, they remain hidden from public scrutiny. This lack of transparency limits our understanding of how these factors may influence the model's behavior, making it challenging to interpret its outputs or predict performance across different domains or use cases.
Legal and ethical considerations also need more transparency about data sources. Questions linger about potential copyright issues or the use of personal information in training. With clear information about the provenance of the training data, it becomes easier to assess whether the model's development adhered to ethical guidelines and legal requirements regarding data usage.
Meta's approach with Llama 3 starkly contrasts some other open-source AI initiatives that have made concerted efforts to be more transparent about their training data. A comparison with other prominent open-source language models reveals significant data transparency and usage flexibility disparities.
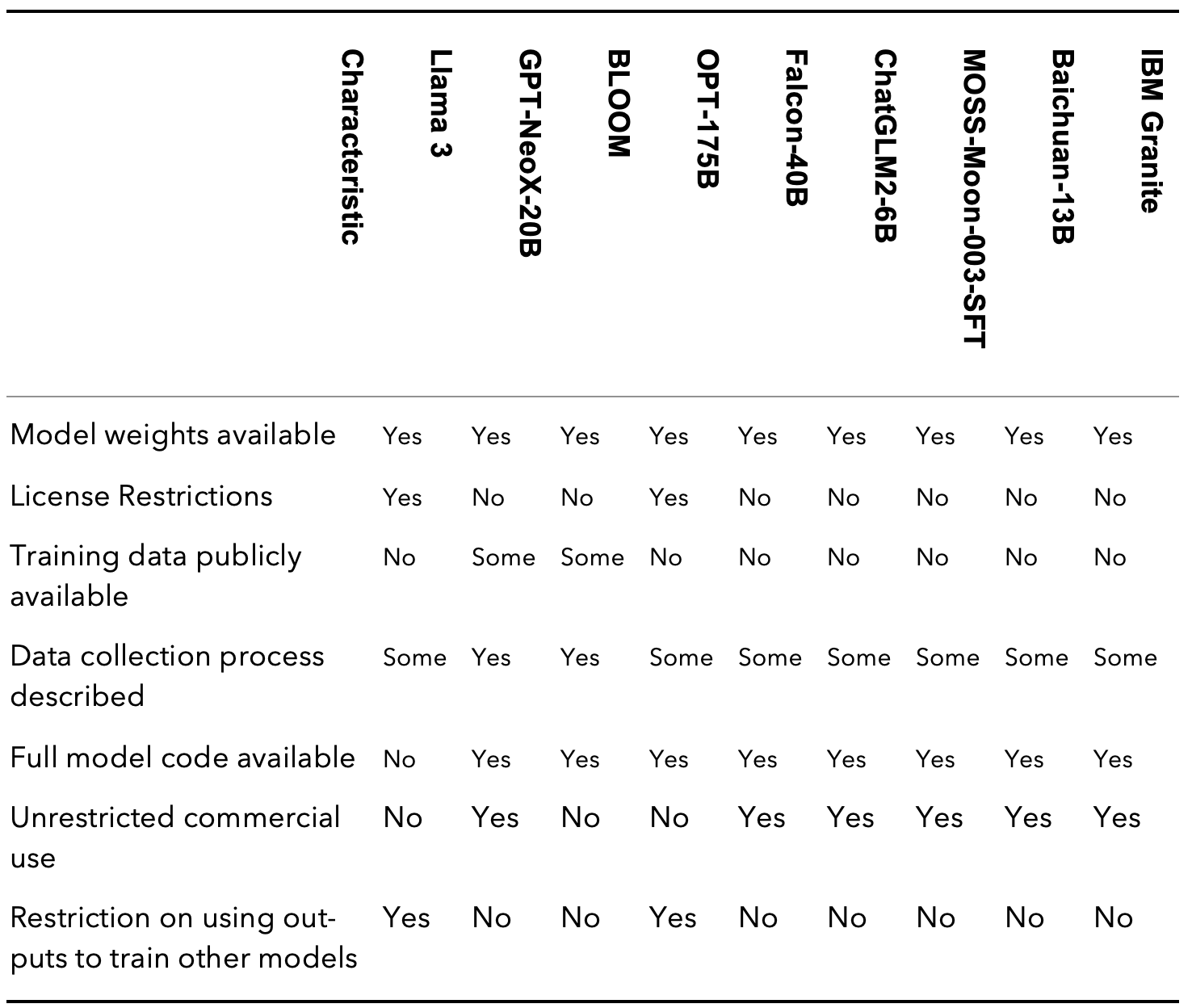
As seen from this comparison, while Llama 3 is more accessible than fully closed models, it falls short in data transparency and usage flexibility compared to other open-source efforts, even from a software vendor such as IBM (disclosure: I was IBM’s Chief AI Officer). Others have made more substantial efforts to provide information about their training data and processes and allow more unrestricted use of their outputs.
Interestingly, the open-source Chinese models and Falcon-40B from Technology Innovation Institute share similarities with Llama 3 regarding limited data transparency. However, they differ significantly in their licensing approach, offering more permissive terms under the Apache 2.0 license. This license allows unrestricted commercial use and does not prohibit using model outputs to improve other AI systems, fostering a more open ecosystem for innovation.
The Falcon-40B model from TII stands out for its high performance and open licensing combination. While it doesn't provide full transparency about its training data, its permissive license allows for broad usage and adaptation, making it an attractive option for researchers and commercial applications.
While the Chinese models need to be more fully transparent about their training data, they represent significant efforts to create open-source alternatives in a market often dominated by Western tech giants. Their permissive licensing could foster a vibrant AI development and application ecosystem in China and beyond.
These differences in transparency and openness have far-reaching implications. Models with greater transparency enable more thorough scientific scrutiny, fostering trust in their capabilities and limitations. They allow for more comprehensive bias and fairness audits, ensuring that AI systems do not perpetuate or exacerbate societal inequities. Moreover, transparent models facilitate faster innovation, as researchers can build upon known foundations rather than working in isolation.
Safety Considerations
Developing advanced AI models like Llama 3 brings complex challenges, chief among them being the imperative to ensure these powerful systems are deployed safely and ethically. To their credit, Meta's technical report on Llama 3 showcases an industry-leading focus on safety and responsible AI development, demonstrating a keen awareness of the potential risks associated with large language models and a proactive approach to mitigating these concerns.
Meta's commitment to comprehensive safety evaluations is at the forefront of its safety initiatives, including open-sourcing these tools (I assume under the same license, but it needs to be clarified). Recognizing that the impacts of AI systems can be far-reaching and multifaceted, the company has undertaken extensive assessments across a wide spectrum of risk categories. These evaluations delve into critical areas such as toxicity, bias, and the potential for misuse, reflecting an understanding that the ethical implications of AI extend far beyond mere technical performance metrics and include red teaming. This holistic approach is why it is an industry-leading approach.
The focus on toxicity (which leads me to believe the data has a large component of social media data) is particularly crucial in an era when online discourse can quickly become harmful or abusive. By rigorously testing Llama 3's outputs for toxic content, Meta aims to prevent the model from generating or amplifying harmful language. This effort is essential for protecting individual users, maintaining the integrity of online spaces, and fostering healthy digital communities.
Bias in AI systems has been a persistent concern in the tech industry, with numerous examples of models inadvertently perpetuating or exacerbating societal prejudices. Meta's attention to bias evaluation in Llama 3 represents an important step toward creating more equitable AI systems. By actively seeking out and addressing biases in the model's training data and outputs, Meta strives to develop an AI that treats all users fairly and doesn't disadvantage particular groups or perpetuate harmful stereotypes.
The potential for misuse is another critical area of focus in Meta's safety evaluations. As language models become increasingly sophisticated, concerns have arisen about their potential to be used for malicious purposes such as generating disinformation, creating deepfakes, or automating cyber-attacks. By thoroughly assessing these risks, Meta aims to implement safeguards that prevent Llama 3 from being co-opted for harmful purposes while preserving its utility for beneficial applications.
A particularly noteworthy aspect of Meta's safety approach is their emphasis on multilingual safety. In our globalized world, AI systems must be safe and ethical in English and across diverse languages and cultures, representing the global community. By extending its safety efforts to multiple languages, Meta acknowledges the global impact of their technology, taking steps to ensure that users worldwide can benefit from Llama 3 without being exposed to undue risks or harms.
This multilingual approach to safety is especially important given the varying cultural contexts and sensitivities across different languages and regions. What might be considered acceptable or harmless in one culture could be deeply offensive or problematic in another. By addressing safety concerns across multiple languages, Meta demonstrates a commitment to creating an AI system that is truly global in its ethical considerations.
Beyond these evaluation efforts, Meta has also invested in developing system-level protections to enhance the safety of Llama 3. The creation of Llama Guard 3, a specialized classifier designed to detect potentially harmful inputs or outputs, represents a significant advancement in AI safety. This additional layer of protection safeguards against unintended harmful behaviors, acting as a filter to catch problematic content before it reaches users.
The implementation of Llama Guard 3 showcases Meta's understanding that safety in AI systems cannot be achieved through training alone. By incorporating an active monitoring system, they create a more robust safety framework that can adapt to new challenges and evolving threat landscapes. This approach aligns with best cybersecurity practices, where multiple layers of protection are used to create a more resilient system.
One of the most commendable aspects of Meta's approach to safety in Llama 3 is its commitment to transparency. By openly discussing its safety measures and releasing the results of its evaluations, Meta contributes valuable insights to the broader conversation on responsible AI development. This transparency allows for external scrutiny and validation of its safety claims and provides a model for other AI developers to follow.
The importance of this transparency cannot be overstated. As AI systems become increasingly integrated into various aspects of our lives, public trust in these technologies is paramount. By being open about both Llama 3's capabilities and limitations, as well as the steps taken to ensure its safe deployment, Meta helps to build this trust and sets a standard for responsible disclosure in the AI industry.
The safety features implemented in Llama 3 could prove particularly valuable for startups and smaller organizations looking to leverage AI technology. Building responsible AI applications from the ground up can be resource-intensive, especially for companies without the extensive research capabilities of tech giants like Meta. By providing a model that has already undergone rigorous safety evaluations and incorporates built-in protections, Meta could lower the barrier to entry for ethical AI development.
These safety features help startups mitigate some risks associated with deploying powerful language models. For instance, the multilingual safety considerations could be especially beneficial for startups aiming to create global applications, saving them the effort of conducting extensive cross-cultural safety evaluations. Similarly, the system-level protections offered by Llama Guard 3 could provide an additional layer of security for startups concerned about the potential misuse of their AI-powered applications.
However, while these safety features are a significant step forward, they do not eliminate all risks associated with AI deployment. Startups and other organizations utilizing Llama 3 or similar models should still conduct safety assessments and implement additional safeguards tailored to their specific use cases and target audiences.
Meta's focus on safety and responsible AI development and providing these tools to the broader community represents a significant contribution to AI safety and responsible AI. Meta has set a high standard for responsible AI development through comprehensive safety evaluations, multilingual considerations, system-level protections, and a commitment to transparency. These efforts not only enhance the safety and reliability of Llama 3 itself but also provide valuable insights and tools f or the broader AI community. As we explore AI development and deployment initiatives like these, we must ensure that the tremendous potential of AI is realized in a manner that is safe, ethical, and beneficial to society.
Implications for Startups and Investors
This is a complex situation. While Llama 3 offers state-of-the-art capabilities, its restricted license and limited transparency exemplify the "faux-pen source" approach. For startups considering Llama 3, the model's powerful performance must be weighed against its significant limitations. The user limit on commercial use could become a major obstacle for rapidly scaling businesses—which I’m sure you plan on. Additionally, the restriction on using Llama 3's outputs to train other models may hinder startups looking to develop specialized AI solutions or innovate beyond Llama's capabilities.
In contrast, several other open-source models such as Granite, Falcon, GPT-NeoX-20B, Falcon-40B, the open-source Chinese models (ChatGLM2-6B, MOSS-Moon-003-SFT, and Baichuan-13B) and many others offer greater flexibility under the Apache 2.0 license. These open-source options allow unrestricted commercial use and don't prohibit using their outputs to improve other AI systems, potentially fostering a more innovative ecosystem.
Investors should carefully consider the implications of a startup's choice of AI model. While Llama 3 may offer performance advantages, its "faux-pen source" nature could limit a company's ability to scale or pivot in response to market demands. Projects built on more permissively licensed models might have greater flexibility to innovate and adapt, potentially leading to more sustainable long-term growth.
The lack of publicly available training data across most models, including Llama 3, raises concerns about reproducibility and bias assessment. Startups should develop strategies to complement these models with proprietary, well-understood datasets to mitigate potential risks and create more reliable AI applications.
A multi-model strategy may be prudent for startups and investors alike. By diversifying across different AI models, companies can hedge against the limitations of any single platform and take advantage of the strengths of various approaches.
Engaging with developer communities, particularly those that promote more open models, can provide valuable insights and potential collaborations. For Llama 3 users, staying informed about Meta's evolving license terms and community guidelines is crucial.
While Llama 3's "faux-pen source" approach offers powerful capabilities, it has significant restrictions that may limit its long-term viability for some startups. While potentially less advanced in some aspects, the truly open-source alternatives offer greater flexibility and could foster more innovative and adaptable AI ecosystems. When charting their course in the AI landscape, startups and investors must carefully weigh these factors, considering current performance, long-term scalability, innovation potential, and regulatory compliance.
Let’s Wrap This Up
As we navigate the open-source AI ecosystems, emerging "faux-pen source" models like Llama 3 present opportunities and challenges that must be carefully considered. While these models offer powerful capabilities and increased accessibility compared to fully closed systems, they fall short of the true openness that characterizes genuine open-source initiatives.
For startups and investors in the AI space, the choice of underlying models is more critical than ever. Llama 3's impressive performance must be weighed against its restrictive license terms, which could potentially limit scalability and innovation. In contrast, open-source alternatives like Granite, GPT-NeoX-20B, Falcon-40B, and various Chinese models offer greater flexibility and the potential for unrestricted growth and adaptation.
The need for more transparency regarding training data across most models, including Llama 3, remains a significant concern. This opacity hinders comprehensive bias assessments and reproducibility efforts, crucial for building trustworthy and ethical AI systems. Startups should complement these models with proprietary, well-understood datasets to mitigate risks and enhance reliability.
A multi-model strategy may prove most prudent for startups and should be an important metric for the diligence process of investors. By diversifying across different AI models, companies can hedge against the limitations of any single platform while capitalizing on the strengths of various approaches. Engagement with developer communities and staying informed about evolving license terms will be crucial for navigating this rapidly changing landscape.
As we at 1Infinity Ventures continue to champion responsible, safe, and green AI development, we recognize the importance of these considerations in shaping AI's future. The path forward will likely require ongoing collaboration between tech companies, the open-source community, and regulatory bodies to strike a balance that fosters innovation while ensuring transparency, fairness, and ethical use of AI technologies.
We commend Meta on its commitment to AI safety through the development of its AI safety tools and their free availability. However, for Meta to live up to Zuckerberg’s and LeCun’s rhetoric about the value of open-source AI and generative AI, Meta needs to adopt a more standard open-source license, such as the Apache 2.0 license, which is the norm in the AI world. Until they do this, the rhetoric is just that and plays into the hands of Meta’s detractors.
In this era of AI advancement, the most successful ventures will be those that can adeptly navigate the nuances of model selection, data transparency, and licensing restrictions. By carefully weighing these factors and prioritizing ethical considerations, we can work towards an AI future that is not only technologically advanced but also responsible and inclusive.
The journey towards truly open, responsible AI is ongoing. Through informed decision-making and collaborative efforts, we will realize AI's full potential to benefit society as a whole. As we explore and invest in this exciting field, let’s remain committed to fostering an AI ecosystem that is innovative, ethical, accessible to all.

The road ahead for AI is both exciting and challenging. As we witness advancements in AI capabilities, we must ensure that AI advancements are directed toward creating a more equitable and sustainable world. By focusing our investments and efforts on startups that embody the principles of responsible AI development, we can help steer the industry toward a future where AI truly serves humanity's best interests.
Whether you're a founder seeking inspiration, an executive navigating the AI landscape, or an investor looking for the next opportunity, Silicon Sands News is your compass in the ever-shifting sands of AI innovation.
Join us as we chart the course towards a future where AI is not just a tool but a partner in creating a better world for all.
Let's shape the future of AI together, staying always informed.
INVITE DR. DOBRIN TO SPEAK AT YOUR EVENT.
Elevate your next conference or corporate retreat with a customized keynote on the practical applications of AI. Request here
SHARE SILICON SANDS NEWS WITH A FRIEND.
If you enjoy this newsletter and want to share it with a friend/colleague, please do.
INVITE: APAC Family Office & VC Online Conf.
Join us & 500+ family offices, VCs, venture studios, founders & angels at the APAC Family Office & VC Online Conf on Sept 20th at 3 PM Singapore for 3 hours (join any time). It’s a virtual event on Zoom.
Must-attend if you’re investing/fundraising/partnering with Singapore, Australia, India, China, Indonesia, New Zealand, Thailand, Malaysia, South Korea, Taiwan, Hong Kong, Vietnam, Philippines & other Asia-Pacific countries.
Register for free or buy a paid ticket: https://inniches.com/apac

LAST WEEKS PODCASTS:
🔊 HC Group published September 11, 2024
🔊 American Banker published September 10, 2024
UPCOMING EVENTS:
SAP UX Immersive
Palo Alto, CA 25 Sep '24
New York, New York 1-2 Oct ‘24
Kuwait, Kuwait City 8-9 Oct ’24
San Francisco, CA 11-13 Oct ’24
HMG C-Level Technology Leadership Summit
Greenwich, CT 17 Oct ’24
FT - The Future of AI Summit
London, UK 6-7 Nov ‘24
The AI Summit, New York, NY Dec ‘24
Unsubscribe
It took me a while to find a convenient way to link it up, but here's how to get to the unsubscribe. https://siliconsandstudio.substack.com/account

Share this post